

目前Vibe coding领域热度高涨,令人惊讶的是,近期一位技术专家成功解析了热门AI编程工具Cursor和Windsurf的核心算法。
今天凌晨,名为Nir Diamant的技术大咖发布了一篇深度分析文章,详细阐述了Cursor和Windsurf背后的算法原理。这就如同使用抖音时需要掌握其推荐机制一样,身处Vibe Coding的我们也应迅速理解与我们对话的编程助手的思维模式。这篇文章内容丰富,值得大家仔细阅读和收藏。

市场上存在众多AI编程工具,尽管有许多Copilot类产品,但能够真正吸引开发者的,仍然是Cursor和Windsurf。这两款工具的魅力在于它们不仅帮助编程,更像是一个理解你构建目标的合作伙伴。
那么,这两款工具的运作原理究竟如何?背后又涉及哪些算法和系统呢?接下来,我们将深入探讨这些干货。

Cursor和Windsurf
如何解读你的代码
要让AI编程助手真正发挥效用,它必须全面理解代码库和开发者意图。Cursor与Windsurf均采用了先进的上下文检索技术,使得AI能够有效“解读”你的代码。
首先,我们来看看Cursor的运作方式。
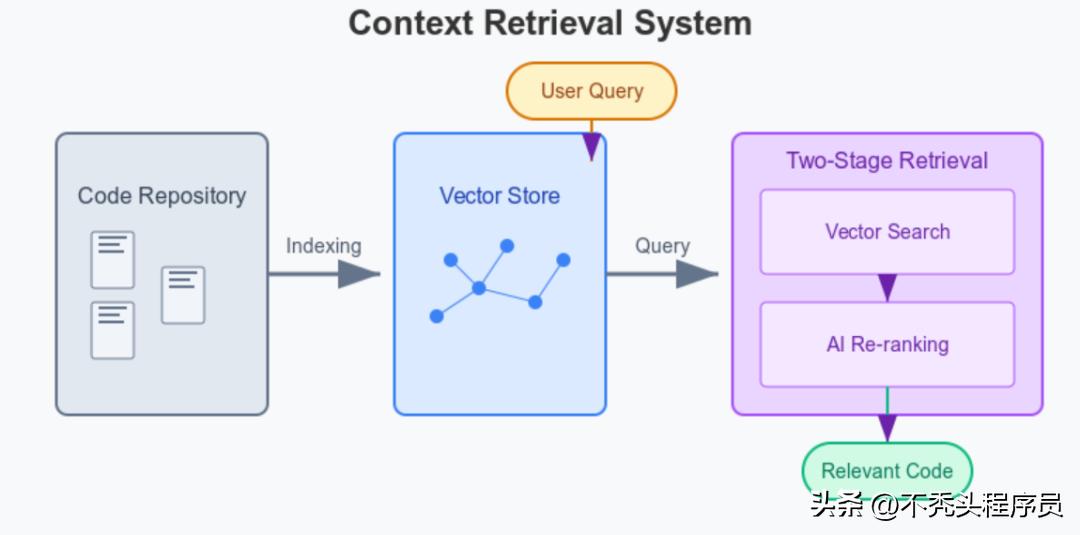
- Cursor将整个项目索引到一个向量数据库中,这可以视作创建了一张智能代码地图,将语义相似的代码进行归类。
- 在进行索引时,它运用了专门设计的编码器模型,尤其注重注释和文档字符串,以便更好地捕捉每个文件的功能和意图。
- 当用户提问时,Cursor会采用“两阶段检索”策略:
标题:探索智能代码助手的两阶段检索机制
通过向量搜索,系统能够迅速识别出潜在的相关代码片段。
- 接着,AI 模型会依据相关性进行排序。就像一个认真负责的图书管理员,首先收集所有与某个主题相关的书籍,随后再精挑细选出真正符合需求的内容。
这种两阶段的检索方式,显然比传统的关键词或正则表达式搜索更加高效,尤其在处理复杂的代码行为问题时,优势尤为明显。
- 此外,用户还可以通过 @file 或 @folder 标签来明确指定文件,仿佛在对系统说:“请查看这些章节。”
- 同时,当前打开的文件及光标周围的代码也会自动被纳入考虑范围。
接下来,我们将探讨Windsurf的相似方法。
- Windsurf的索引引擎同样会全面扫描代码库,创建一个可供搜索的代码地图。
- 它采用基于大型语言模型的搜索工具,声称其精确度优于传统的嵌入式搜索,能够更好地理解用户的自然语言查询,进而找到相关的代码片段。
- 在提供建议时,系统不仅会考虑当前文件,还会从整个项目中提取相关文件,确保“项目级别的系统感知”。
- 此外,它还具备“上下文固定”功能,用户可以将设计文档等重要信息固定在一个“AI 永远能看到的公告板”上,确保AI在任何时候都能参考这些内容。

Cursor与Windsurf
是如何进行“思考”的
作者指出,这两款助手的“思考方式”是通过精心设计的提示和上下文管理策略来实现的。
首先,我们来看看Cursor的提示结构。
- 它采用结构化的系统提示,使用和等标签来组织不同类型的信息。
- 系统会明确告知AI行为规范,从而塑造其与用户的互动方式:
- 避免不必要的道歉。
- 行动前要进行解释。
- 不直接在聊天中输出代码,而是使用专门的代码编辑器进行。
- 此外,还运用了“上下文学习”技术:在提示中展示正确的工具调用或响应标准格式,就像是用实例来指导新手。
而Windsurf的机制则有所不同,其Cascade Agent更加综合——
- 它结合了自定义规则(AI Rules)和可持续记忆机制(Memories)。
Windsurf与Cursor的智能执行机制比较
值得注意的是,Cursor与Windsurf之间存在一个共性:两者都配备了高效的上下文窗口管理系统,能够处理大量文本。它们会对信息进行压缩,优先保留与当前任务最相关的内容。

这两者是如何完成任务的呢?
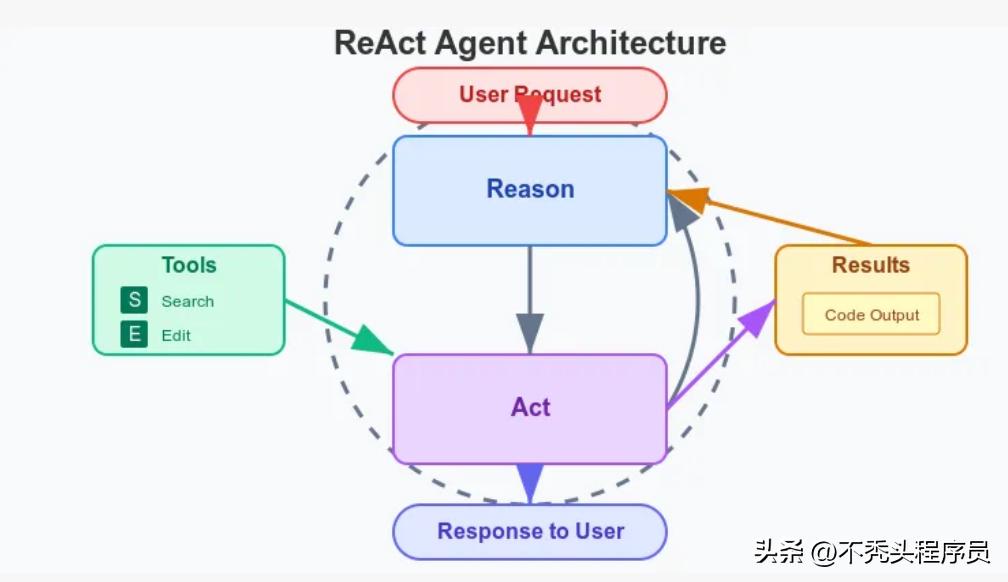
Cursor和Windsurf共同采用了被称为ReAct(推理与执行结合)的模式,将语言模型转化为多步骤的智能代理。
首先来看Cursor的步骤。
Cursor代理以循环的方式进行操作:AI选择工具→阐释意图→调用工具→查看结果→决定下一步。其可利用的工具包括:代码搜索、文件读取、代码编辑、执行shell命令,甚至在线查阅文档。
需要强调的是,Cursor进行了一项重要的优化——“特种diff语法”:这使得AI无需重写整个文件,而是建议具体的“语义补丁”,并通过一个独立的快速模型将其合并。这种方式提高了效率,并减少了错误的发生。
与此同时,Cursor在沙盒环境中执行实验代码,确保不会对实际项目造成影响。
例如,当你要求它“修复认证Bug”时,它可能会先搜索相关的代码文件,然后进行阅读、修改,并运行测试以验证修复的成功与否。每个步骤都会告知你正在发生的事情。值得一提的是,它会限制自我修复的循环次数(例如“不超过3次”),以防止进入死循环。
此外,Cursor还引入了“专家混合机制”:它利用强大的大模型(例如GPT-4或Claude)进行决策推理,并用小模型来执行具体任务,仿佛由一位高级架构师制定方案,而专业施工队负责实施。
接下来,我们来看看Windsurf。Windsurf的Cascade同样具备类似机制,但更强调其“AI流”(AI Flows)的设计。
生成计划 → 修改代码 → 请求用户确认 → 执行代码 → 分析结果 → 提出修复。
在你发出请求后,Cascade会生成执行计划、进行代码修改并征求你的确认,随后才会执行代码。如果你表示同意,它还可以在集成的AI终端中运行代码并分析结果,进一步提出修复建议。
更为强大的是,Windsurf的代理系统能够在一个流程中串联多达20个工具调用,而无需你手动干预。这些工具包括自然语言代码搜索、终端命令、文件编辑,以及连接外部服务的MCP协议。这种能力使得Cascade能够一次性完成如安装依赖、配置项目和实现新功能等复杂任务。
更令人印象深刻的是,如果你在AI执行过程中手动调整了代码,Cascade会立即感知并自动调整所有相关部分,真正实现了与AI的实时协作。

智能系统的核心
模型设计
毫无疑问,这两款出色的工具都依赖于多个 AI 模型来执行各类任务,以此在响应速度和输出质量之间找到最佳平衡。然而,它们在具体实施策略上却存在显著差异。
Cursor 的模型体系如下:
- 采用“嵌入-思考-执行”三阶段代理循环(Embed-Think-Do Agent Loop)。
- 系统会根据不同的任务类型选择最适合的模型进行处理。
- 例如,使用 100k tokens 的 Claude 模型来处理整个项目的上下文和复杂推理,从而实现更深层次的理解。
- 生成向量嵌入的模型与 OpenAI 的 text-embedding-ada 相似。
- 在代码补全和编辑方面,系统会依据任务的复杂程度及用户的设置动态选择合适的模型。
- 其核心创新在于:通过智能动态路由机制,依据场景智能平衡大模型与小模型的应用,达到优化质量与响应速度的目的。
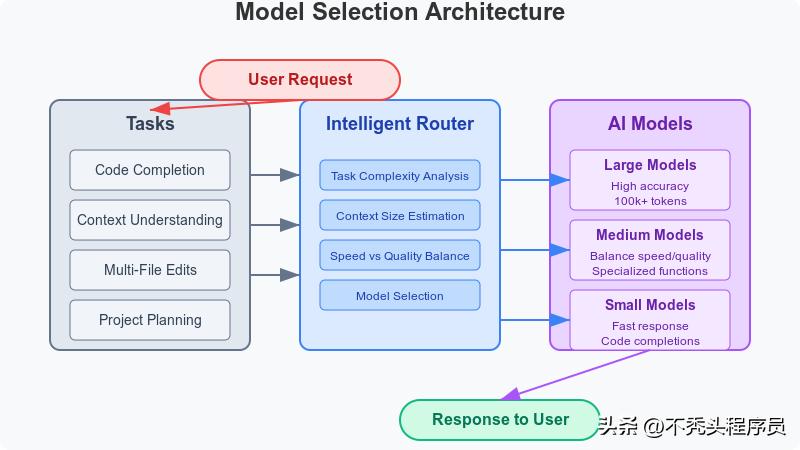
而 Windsurf 的模型策略则展现出更为清晰的方向:
- 投入大量资源开发自有的代码专用模型,基于 Meta 的 Llama 架构:
- 70B 参数的基础模型适合处理日常任务;
- 405B 参数的高级模型则应对更为复杂的挑战。
- 支持用户选择 GPT-4 或 Claude 等外部模型,展现出极高的灵活性。
- 在模型选择上:小模型适合快速建议,大模型则处理多文件的大规模改动,确保系统为每项任务匹配最合适的“智能核心”。
- 通过token-by-token的实时流式响应,用户能够目睹代码逐步生成的过程。
- 当生成的代码出现错误时,系统会自动识别并尝试进行修复,无需用户的手动操作。
- 该机制能跟踪文本光标的位置,以便指导代码的补全,并预测接下来的可能修改点。
- 系统会在后台持续更新向量索引,确保新写入的代码能够立即被检索,AI对代码库的理解始终保持最新状态。
- 它同样支持流式输出,以保持“沉浸式的工作流程”。
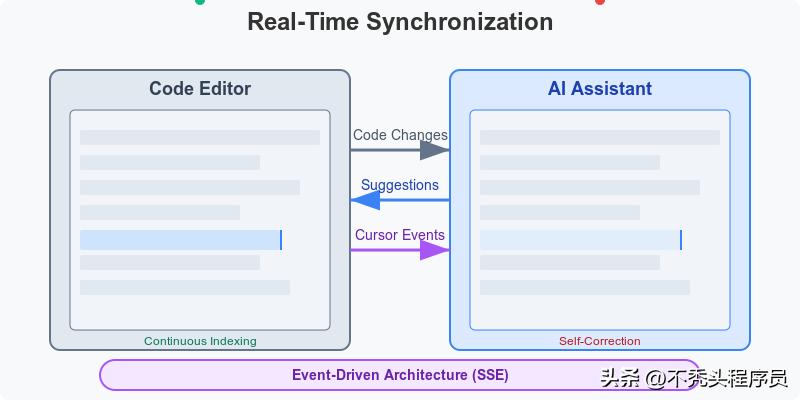
- Cascade代理会在代码修改的瞬间感应到变化,并即时调整工作计划。
- 建立在事件驱动的架构之上,文件保存和文本修改等操作都会触发AI进行重新推理。
- 通过使用服务器推送事件(SSE)来保持编辑器、终端和聊天窗口之间的同步。
- 在代码运行时如果发生错误,AI能够迅速捕捉并提供解决方案,无需用户手动操作。
探索智能编程助手的同步机制

如何实现实时同步(Sync机制)
为了确保编程体验的流畅性,实时适应用户操作显得尤为重要。这两种系统都具备巧妙的同步机制。
Cursor的机制采用token级别的流式响应,具体如下:
而Windsurf的核心目标则是维护“顺畅的工作体验”。
ps:这样的设计使得AI如同一个全神贯注的编程伙伴,始终关注着你的代码并主动提供帮助。
最后,值得注意的是,本段内容是作者Diamant经过长时间深入研究和整理大量公开资料后,对Cursor和Windsurf这两款AI工具的“核心机制”的理解,尽管其中的一些细节可能会随着后续版本的更新而有所变化。

网友:难怪了!
终于明白Cursor理解能力不佳的原因了
文章发布后,众多网友对Diamant的研究成果表示赞赏,并且很多人对“大模型”的不足表示理解和宽容。
例如,一位网友恍若领悟,意识到Cursor并不会一次性将全部代码存入内存,而是构建了一种代码的“智能地图”(RAG),并仅在需要时才会调用相关的向量索引。
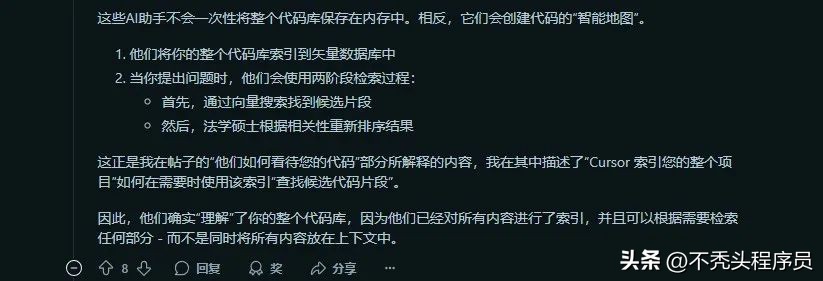
然而,另一位网友对此表示不满,他指出这种方法恰恰是造成编码工具理解能力差的原因。
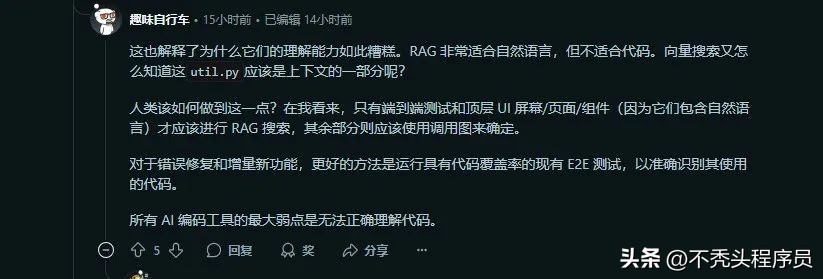
“RAG虽然适用于非自然语言,但对于代码而言却不太合适。”这位网友还举了一个例子:向量搜索如何能确定util.py应该作为上下文的一部分呢?
他认为,只有在端到端的测试和高层次的UI界面/页面/组件(因为包含自然语言)中,才能进行RAG搜索,而其他部分应通过调用图来识别。
至于错误修复和新增功能,他建议更有效的方法是运行现有的E2E测试,确保代码覆盖率,以便准确识别并利用代码。
因此,深入理解工具背后的核心逻辑,能够为开发者提供全新的视角,从而为这些硅基生命的编程伙伴提出更有价值的改进建议。
这对于日益兴起的Vibe Coding而言,意义深远。虽然当前大家对LLM编程工具的态度相对宽容,但对这条赛道上众多参与者来说,揭示其背后的算法机制通常能帮助用户提出更优的修改建议。
昨天,我了解到在某个技术交流群中有朋友分享了他们的反馈:
Cursor生成一个项目代码的速度很快,仅需一两分钟,但运行时却常常出现很多bug,尤其是语义错误,修复bug的时间也很长,常常需要超过半个小时。
Cursor的代码理解困境及用户反馈
我们可以看到,Cursor在理解代码方面确实存在显著的缺陷。这种现象可能不是短时间内就能通过大模型来解决的。一位网友深入分析了这一问题的根源:

因此,若Cursor希望改善其“理解不佳”的问题,或许应该认真倾听用户的反馈:使用RAG来处理代码上下文效果欠佳,尝试采用调用图可能会更加有效!

Please specify source if reproduced深入解析 Cursor 与 Windsurf 的核心算法机制! | AI工具导航