
在人工智能模型训练的复杂过程中,学习率常被认为是调参中最具挑战性的超参数之一。学习率不仅关系到模型的收敛速度和稳定性,还深刻影响最终的性能表现。本文将通过系统性分析,详细探讨学习率的本质、调参技巧、常见误区以及最新研究,帮助读者从理论到实践全面理解这一关键概念。
 引言:学习率的起源
引言:学习率的起源
在人工智能的广阔天地中,有一个名词虽然不如“神经网络”或“深度学习”那样响亮,却在AI学习的成败中扮演着至关重要的角色——那就是“学习率”(Learning Rate)。
- 它的定义是什么?简单来说,学习率是AI训练过程中的关键“调速器”,由工程师设定的数值,直接影响着AI学习的速度及效果。
- 它的来源是什么?学习率是源于一种名为“梯度下降”(Gradient Descent)的优化算法,这个算法是AI学习过程中最常用的“导航工具”,而学习率则是其中最重要的参数之一。它并非AI自我学习的结果,而是人类为AI设计的“探险规则”。
- 它的作用是什么?学习率的主要功能是“控制步伐”。在学习过程中,AI会找到一个“最佳方向”,但具体的步伐长度则完全由学习率决定,它是AI学习效率和最终成果的关键所在。
引言:探索最优性能的旅程
想象一下,人工智能就像一位孤独的寻宝者,它的任务是穿越一片辽阔且终年被迷雾笼罩的艰险地带,寻找传说中的“最优性能之谷”。在这座山谷的深处,埋藏着终极宝藏:对某项任务的完美掌握,无论是图像识别、语言翻译,还是音乐创作。
这片险峻的地势是由一张名为“损失函数”的隐形地图所构成。这个数学公式精确地测量AI的预测结果与真实答案之间的差距,从而描绘出整个地形。科学家们诗意地称之为“损失地貌”。
在这幅地貌中,海拔高度代表了AI所犯的错误,猎人所处的高度越高,表示其错误越多。寻宝的目标,就是不断移动,尽量降低损失值。
而整个探险的成败,悬而未决于猎人在每一个时刻必须做出的关键选择:下一步该迈出多大。这“一步之遥”的大小,正是我们今天讨论的主角——学习率(Learning Rate)。它是AI训练者在旅程开始前设定的最重要的“超参数”之一,将直接影响这场寻宝之旅的成就与否。
在深入讨论之前,我们需要区分猎人所带装备的两大核心类别:“参数”和“超参数”。
- 参数(Parameters):这些是AI模型内部可以自主学习和调整的内容。在我们的比喻中,参数相当于猎人在地图上所处的具体坐标(经度、纬度、海拔)。AI的“学习”过程就是不断调整这些坐标,寻找最低点。这些参数(也常被称为“权重”)构成了AI知识网络的基础。
- 超参数(Hyperparameters):这些是AI无法自主学习的外部设定,必须由工程师在寻宝之旅开始前配置好。学习率便是最典型的超参数。在比喻中,它们就像猎人选择的装备:他穿什么品牌的登山鞋、使用多长的登山杖、背包里带多少食物。这些选择会深刻影响寻宝的效率和结果,但猎人在探险过程中无法改变。
本文将围绕这关键的一步展开讨论。
第一章:藏宝图与魔法导航
地形概述(损失函数)
首先,我们需要更深入地了解这片“损失地貌”。它并不是一座简单的山丘,而是由连绵起伏的山脉、深邃的峡谷、陡峭的山脊以及众多迷惑人的小洼地组成的复杂地形。宝藏猎人的目标是找到整片地貌的绝对最低点,即“全局最小值”(Global Minimum),那里才是宝藏的真正所在。这片地貌的基础是由一张名为“损失函数”(Loss Function)的隐形地图所定义。这个数学公式精确衡量AI预测结果与真实答案之间的差距。
这里的“损失 (Loss)”是一个核心概念。简单来说,它是衡量“我们预测错误的程度”的数值。如果AI预测明天会下雨(预测值为1),但实际上是晴天(真实值为0),那么损失值就会很高;而如果预测基本正确,损失值则会相对较低。因此,猎人的海拔高度实际上就是这个损失值——海拔越高,错误越大。整个寻宝的目标是通过不断移动,将损失值尽可能降低。
可靠的向导(梯度下降)
我们想象中的猎人被浓雾笼罩,无法看清周围的地势,只能依靠脚下的触感来判断方向。为了找到前路,它借助了一种名为“梯度下降”(Gradient Descent)的魔法罗盘。这个罗盘不会指向北方,而是始终指向当前地点的最陡下坡方向,这个方向在技术上被称为“负梯度”(Negative Gradient),是减少错误、降低海拔的最佳路径。
那么,梯度下降 (Gradient Descent)是如何运作的呢?其实过程非常简单,犹如盲人下山。猎人在某个地点,会用脚在周围试探,寻找坡度最陡的方向,这个“最陡的下坡方向”就是梯度。随后,他便朝着这个方向迈出一步。在到达新位置后,重复同样的过程:试探、找到最陡的方向、再迈出一步。这个“试探-迈步”的循环不断进行。理论上,只要每一步都朝着最陡的方向走,猎人最终肯定能到达一个洼地的底部。这种简单而有效的策略,正是现代AI学习的核心驱动力。
关键一步(学习率的作用)
学习率(通常用希腊字母 η 表示)这个超参数,恰恰决定了猎人沿着罗盘指示的方向,要迈出多远的一步。每一步都是对AI内部“参数”(Parameters)或“权重”(Weights)的微小调整——这些参数正是其知识网络的基石。整个训练过程就是这系列步伐的反复:查看罗盘,迈出一步;再查看罗盘,再迈出一步。这个过程会迭代成千上万次,甚至数百万次,直到猎人到达一个再也无法下去的地方。
这个过程揭示了一个深刻的道理:尽管梯度下降这个魔法罗盘非常强大,但它也是极度“短视”的。它只能确保当前这一步是局部最优的,即能最快地降低眼前的高度,却对前方的整体地形一无所知。这种短视正是学习率(步长)至关重要的根本原因。若缺乏合适的步长策略,一系列局部最优的决策并不能保证最终达到全局最优。梯度下降在每次迭代中计算出的最陡下坡方向,是一种“贪婪”的选择,因为它总是选择能带来最直接回报的路径。如果步长选择不当,可能会造成灾难性的后果。因此,学习率在这个过程中的角色至关重要,它在短视策略与长期目标之间取得平衡,使学习率不仅仅是一个简单的参数,而是整个优化过程的“战略核心”。
第二章:寻宝路上的挑战:急躁的冒进者与谨慎的爬行者
本章将生动描述两种极端的学习率选择失败模式,以揭示速度与稳定性之间的关键权衡。
急躁的冒进者(学习率过高)
我们先来认识一位极度渴望找到宝藏的猎人,它选择了以巨大的、冲动的步伐(即过高的学习率)前进。这种急于求成的策略将带来一系列严重后果。
猎人的探索之旅:学习率的选择与策略
- 跨越谷底:这位猎人勇敢地一跃而下,竟然轻松跨越了整个山谷,落在对岸的山坡上,甚至比起点更高。他与宝藏擦肩而过,未能如愿。
- 反复震荡:更常见的情形是,猎人被困在山谷中,左右之间疯狂往返。他的探险记录(损失曲线)充满剧烈波动,时而高耸,时而低洼,始终无法达到稳定状态。
- 彻底失败:最糟糕的结果是,每次跳跃都让猎人到达更高的地方,最后却被完全抛出山谷。他的海拔(损失)剧烈上升,训练任务最终以灾难告终。
谨慎的探索者(学习率过低)
与前者截然不同,另一位猎人由于对“跨越谷底”的风险感到极度恐惧,因此选择了微小而谨慎的步伐(即过低的学习率)前行。
- 缓慢前行:他走向谷底的过程变得异常漫长,似乎没有尽头,这不仅浪费了大量时间,还耗费了宝贵的计算资源。在找到宝藏之前,探险队可能因补给耗尽而解散。
- 陷入局部陷阱:这是一个更微妙的危险。在辽阔的地形中,存在许多浅而小的洼地,我们称之为“局部最小值”。这位谨慎的探索者由于步伐过小,容易误入其中。在洼地的底部,四周看似平坦,魔法罗盘也停止了转动。他误以为自己已经找到了宝藏,于是停止了探索,却永远无法得知真正的宝藏之谷就在下一座山脊之后。
这两种极端的情况恰恰反映了经典的“探索与利用”(Exploration vs. Exploitation)困境。高学习率倾向于探索,能够迅速勘察广阔的地形,但也因此面临极大的不稳定性。低学习率则倾向于利用,在某个看似有希望的区域内细致挖掘,但可能会错过整体的机会,满足于微不足道的发现。完美的寻宝之旅必须在这两者之间找到精妙的平衡。
更有趣的是,看似“坏”的行为,往往会带来意想不到的好处。研究表明,高学习率导致的“震荡”有时可能形成一种“良性震荡”(Benign Oscillation)。这种不稳定的波动反而迫使模型去学习数据中那些更细微、更不明显的模式(即“弱特征”),而非仅仅依赖最显眼的规律(即“强特征”)。用比喻来说,那位“急躁的冒进者”由于不断地跨越和跳跃,反而被迫观察到了更广阔、更多样的地形。他无法仅仅依赖最明显的道路下山,这种丰富的探索经历使他成为了更有知识的猎人。当面对一张全新的、前所未见的藏宝图(即测试数据)时,他的表现反而更佳。这个悖论完美地揭示了现代深度学习研究中的复杂性与精妙之处。
第三章:聪明猎人的手册:演进的探索策略
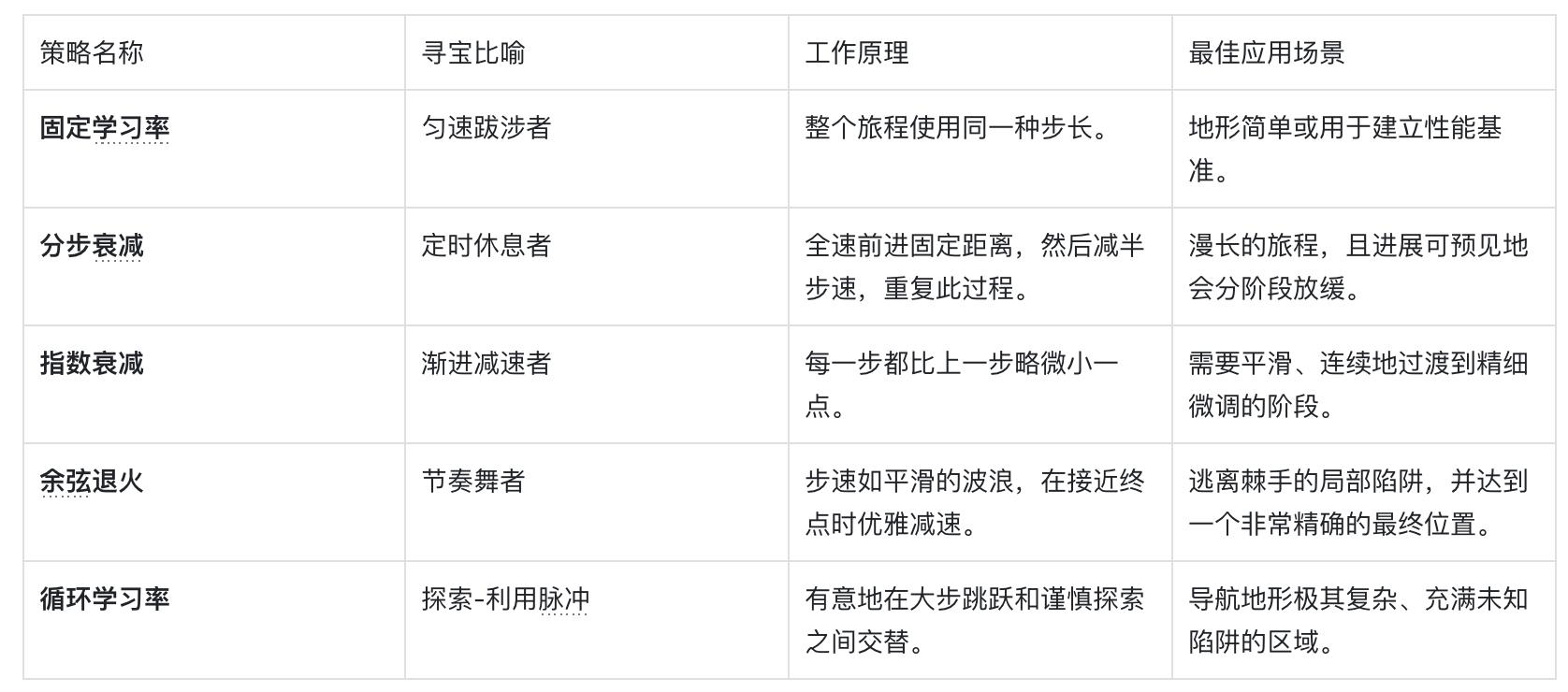
现在,我们的猎人需要学会根据地形和旅程阶段调整自己的步伐。这便引出了“学习率调度”(Learning Rate Schedules)的概念——从固定的步长演变为一种动态的、预先规划的策略。
新手的固定步速
首先,我们需要明确,在整个寻宝过程中始终使用一个恒定的学习率是一种新手的做法。虽然这种方法简单,但很少能达到最佳效果。
从冲刺到慢跑(衰减策略)
一种直观的智能策略是先快后慢。在旅程的初期,地势相对平坦,猎人可以大步前进,迅速接近宝藏的大致范围。随着地形愈发复杂,猎人需要有意识地缩短步长,进行更加细致和精准的搜索,以免与宝藏失之交臂。这种策略主要有以下几种形式:
- 分步衰减(Step Decay):猎人以固定步长前进一段确定的距离(例如一万步),然后果断地将步长减半,并如此反复。
- 指数衰减与基于时间的衰减(Exponential & Time-Based Decay):猎人的步伐随着每一步的前进而平滑、持续地变小,就像长跑运动员在比赛中逐渐消耗体力,速度逐渐放慢。
节奏大师的探索(高级策略)
更复杂的策略甚至涉及到非单调的步速变化,即步长不再单纯减小。
- 余弦退火(Cosine Annealing):猎人的步速遵循平滑的余弦曲线,从快到慢,优雅地减速,有时甚至在周期的末尾会稍微加快。这种节奏性的变化使得模型能够在积极探索和精细微调之间交替,有助于猎人“跳出”那些具有欺骗性的局部陷阱。但是,为什么会叫这个名字呢?“
- 余弦(Cosine)部分是因为学习率变化曲线的形状类似于余弦函数图像的一部分,从最高点平滑下降到最低点,优雅至极。
- 退火(Annealing)则源自冶金学的比喻。在金属加工中,退火是将金属加热到高温后缓慢冷却,以消除内部应力,使结构更稳定、更坚固。在这里,高学习率就像“高温”,使模型的参数可以自由、剧烈地变化(探索);然后逐渐降低学习率,就如同“冷却”过程,让参数最终稳定在一个优质、鲁棒的解(局部最优解)上。
- 循环学习率(Cyclical Learning Rates, CLR):这是一种强大的探索技术。猎人故意让自己的步速在设定的高值和低值之间循环振荡。高速阶段能够帮助他快速跨越广阔而平坦的高原,或从狭窄而陡峭的陷阱(糟糕的局部最小值)中跳脱;而低速阶段则让他在发现有希望的区域时,能够小心谨慎地深入探索。
为了更清晰地总结这些策略,下表将技术术语与其在寻宝比喻中的功能和实际应用联系起来。
第四章:高科技装备:从手动罗盘到自动GPS
本章将讨论“自适应优化算法”(Adaptive Optimization Algorithms),这是一场对猎人工具包的革命性升级。这些高科技装备不再依赖于预设的行进方案,而是能够实时感知地形,并自动调整每一步的步伐。
单一步速的困境
我们再次强调那一核心挑战:损失地貌在不同方向上的陡峭程度截然不同。一个峡谷可能两侧险峻,而谷底却接近平坦——这种地形被称为“病态曲率”(Pathological Curvature)。单一的学习率(即使是动态衰减的)就像强迫猎人无论是在攀爬悬崖还是在草坪上漫步时,都必须迈出同样大小的步伐,显然是低效的。
最初的发明:地形感应靴(AdaGrad & RMSProp)
- AdaGrad(自适应梯度算法):这是第一款自适应装备。它赋予猎人在“左右”移动和“前后”移动时采取不同步长的能力。其工作原理是记录每个方向上地形陡峭程度的历史。对于那些始终陡峭的方向,它会自动缩短步长,以防止猎人在峭壁间来回碰壁;而对于那些一直平坦的方向,它会加长步长,以提高前进速度。
- AdaGrad的致命缺陷:这双靴子存在一个严重的设计缺陷:它只记录不忘。负责缩短步长的机制(一个不断累加的平方梯度之和)会无情增长。最终,所有方向上的步长都会减小至零,导致猎人彻底停滞,被困在原地。
- RMSProp(均方根传播):这是至关重要的升级版。其发明者,深度学习先锋杰弗里·辛顿(Geoffrey Hinton)意识到,这双靴子需要学会遗忘遥远的过去。RMSProp采用了一种“衰减平均”的方式来记录地形的陡峭度,更加看重近期的路况信息。这有效地阻止了步长无休止地缩小,让猎人能够持续前进,不断学习。
那么,什么是衰减平均呢?
深入理解“衰减平均”及其应用实例
让我们通过一个简单的生活例子,来更好地理解“衰减平均”(Decaying Average)这一概念。
这个概念在学术界还有一个更正式的称谓,即指数加权移动平均 (Exponentially Weighted Moving Average,EWMA),但在此我们暂不讨论这个名称。
试想一下,您想了解今天的体感温度有多热。
如果使用普通的平均值,您可能会将过去30天的每日温度相加,然后再除以30。然而,这种做法并不合理,因为您对热感的“体验”显然更受昨日和今日温度的影响,而非一个月前的数据。
衰减平均正是一种更符合人类感知的“喜新厌旧”的平均方法。
它的核心思想是:
- 最近的数据是最关键的,权重最大。
- 过往的数据重要性逐渐降低,权重以指数方式递减。
以下是一个生动的比喻:在杯子中调配果汁。
设想您有一个空杯子,这个杯子里的“混合果汁”代表了我们正在计算的“衰减平均值”。
第一天:气温为30°C。
- 您将苹果汁(代表30°C)倒入空杯中。
- 此时,杯子里的“平均值”就是100%的苹果汁。
第二天:气温降至20°C。
- 您需要更新杯子里的“平均值”,这时您取来一杯橙汁(代表20°C)。
- 但并不是将橙汁全部倒入,而是:
- 首先从杯子中倒掉10%的旧果汁(苹果汁)。
- 然后用新鲜的橙汁将杯子重新填满。
- 此时,杯子里的液体组成变成了:90%的旧果汁(苹果汁)+10%的新果汁(橙汁)。这便是新的“衰减平均值”。
第三天:气温回升至25°C。
- 您再取来一杯葡萄汁(代表25°C)。
- 再次执行相同的操作:
- 从杯子中倒掉10%的“昨日混合果汁”(即昨天的90%苹果+10%橙汁的混合体)。
- 然后用新的葡萄汁填满杯子。
- 此时,杯子里的液体变成了:90%的“昨日混合果汁”+10%的“今日葡萄汁”。
可以看到,最初的苹果汁在第二天仍占有90%,而到了第三天,这个比例则变成了 90% * 90% = 81%。它的影响力不断“衰减”。而每天新加入的果汁则固定维持10%的比例,影响力最大。
那么,为什么称之为“衰减平均”呢?
- 平均(Average):因为杯子中的液体始终是所有历史果汁的混合体,因此它代表了一种平均。
- 衰减(Decaying):因为每一天加入的果汁,其在杯中的比例会随着时间的推移而指数级地减少,影响力逐渐减弱,就像记忆会慢慢消退。
从基础到进阶:Adam优化器的全貌
集大成者:Adam(自适应矩估计)是目前最先进的优化工具,几乎已成为所有AI模型训练的标配。它巧妙地结合了两种强大的技术:
- 地形感应轮胎(源自RMSProp):继承了RMSProp的自适应步长能力,能够根据最新的环境为每个参数独立调整速度。
- 惯性稳定器(源自Momentum):同时融合了“动量”(Momentum)的概念。就像巨石在坡道上滚动,路径若持续向下,则会逐渐加速,这样能够帮助平稳应对颠簸的旅程,克服一些小障碍(梯度噪声),并轻松跨越路途中的小坑(局部最小值)。
为何Adam成为主流选择:因其强大的功能、快速的计算速度以及可靠的性能,Adam相较于前辈们需要的手动调整更少,因而成为深度学习工作者的首选优化器。
从手动罗盘到全自动GPS的演变,实际上是解决具体问题的创新历程。这一过程并非单纯的数学挑战,而是一系列务实的工程突破。最初,梯度下降(SGD)所采用的“一刀切”步长无法适应复杂地形。于是,AdaGrad应运而生,它能够根据历史路况调整步长。然而,AdaGrad的“记忆”过于沉重,最终导致停滞。RMSProp通过引入“遗忘”机制解决了这一问题,更加关注近期的路况。
与此同时,另一个挑战是寻宝路径的颠簸,容易陷入小坑。Momentum通过积累“动量”来解决这个问题,使得猎人得以冲过障碍。
最终,Adam优化器应运而生,它将RMSProp的地形适应能力与Momentum的惯性冲力完美结合,成为了一款高性能的“全地形车”。
这一叙述结构将复杂的优化器发展历程转化为一个普通人能够理解和欣赏的创新故事。
第五章:行前侦察与日志分析
本章将介绍AI训练师管理学习率的实用技巧,这些技能是每位成功探险领队所需掌握的核心能力。
勘察起点(选择合适的初始学习率)
- 经验法则:如何选择第一步的大小?对于使用“Adam全地形车”的新手而言,像0.001这样的默认设置通常是一个极为有效的起点。
- 侦察无人机(学习率范围测试):在更为重要的探险任务中,专家们会在正式出发前派出一架“侦察无人机”。这项由fast.ai推广的技术包括一次快速的初步勘探:猎人从一个极小的步长开始,迅速指数级地增加步长。探险领队会将由此产生的错误率与步长绘制成图,最佳的初始步长通常位于这条曲线最陡峭的下降段,恰好在错误率开始上升之前。这次侦察为整个旅程奠定了一个科学的出发点,而非盲目的尝试。
分析旅程(解读损失曲线)
探险日志:“损失曲线”就如同猎人的探险日志,记录了每个阶段的海拔(损失)。通常会保留两份日志:一份记录主要探险过程(训练损失),另一份则记录在秘密小地图(验证集)上的定期勘测结果,以确保猎人不是在死记硬背地图,而是在真正掌握通用的导航技巧。
解读信号:我们可以学习如何成为解读这些日志的高手:
- 一次成功的寻宝:训练和验证的日志都显示出平滑、稳步的海拔下降,并最终在一个低海拔处趋于平稳。两条曲线之间的差距(“泛化差距”)非常小。
- 冒进者的日志:日志上充满了混乱、尖锐的锯齿状线条,海拔疯狂波动。这是学习率过高的明确信号。
- 爬行者的日志:日志表现出极其缓慢、平稳的下降曲线,且很快就在较高的海拔处停滞。这表明猎人可能被困住,或需要漫长得无法接受的时间才能到达目的地。
- 死记硬背的学霸(过拟合):训练日志呈现出完美的、陡峭的下降曲线,直达极低海拔。但验证日志在初步下降后,却开始反弹。这意味着猎人完美地记住了主地图上的每一块石头和每一棵树,却在新的地形中迷失方向。这是“过拟合”(Overfitting)的典型表现。
高级协同:搜索队规模(批量大小)
比喻:“批量大小”(Batch Size)指的是猎人在决定下一步方向之前,派出勘探周围地形的侦察兵数量。具体来说,AI在学习过程中,并不会一次性处理所有数据(例如一百万张图片),而是分批进行。批量大小就是每一批包含的数据量(例如64张图片)。AI每处理完一批数据,就会根据反馈计算一次梯度,并更新其参数(即猎人迈出一步)。一个小的批量(一个侦察兵)可能带回充满噪声且不可靠的情报,而一个大的批量(数百个侦察兵)则能提供非常准确、稳定的局部地形报告。
相互作用:学习率(步长)与批量大小(搜索队规模)之间存在深刻的联系。规模更大、报告更可靠的搜索队能令猎人更有信心采取更大、更果断的步伐。常见的法则是“线性缩放规则”:若将搜索队的规模扩大一倍,则步长通常也可以扩大一倍。这揭示了在完美探险规划中,不同超参数之间复杂的相互影响。
这些管理学习率的工具,如学习率范围测试和损失曲线,将AI训练从一门“黑箱艺术”转变为“诊断科学”。它们为我们提供了洞察AI内部学习动态的窗口,使基于证据的、迭代式的调试成为可能。没有这些工具,设定学习率就如同在赌博。学习率范围测试提供了先验的证据来指导初始设置,极大地节省了时间和资源。而损失曲线则提供了训练过程的实时反馈。能够从锯齿状的损失曲线中判断“学习率过高”,就如同医生通过心电图诊断心律失常。这将一个神秘的失败转化为一个有明确解决方案(“降低学习率”)的可解问题。这正是现代深度学习能够成为一门可重复与可改进的工程学科,而非简单炼金术的关键所在。
结论:宝藏之路也是探寻之旅
回顾整篇文章,学习率不仅仅是个简单的数值,它象征着人工智能在知识迷宫中探索的节奏与韵律。它并不是一个固定不变的参数,而是一种动态的策略,成为了区分笨拙的尝试与优雅的舞蹈的关键因素,指引着AI在充满无限可能的复杂环境中前行。
我们的寻宝之旅——从最初的步伐简单且单一,到后来的高科技自适应工具,以及复杂的预先设计的行进策略——恰恰反映了人工智能领域的发展历程。这是一个从依赖原始力量到追求智慧的伟大转变。
通过掌握选择合适步骤的艺术与科学,我们现在能够欣赏到每当一个AI模型进行学习时,背后所经历的复杂且充满策略的过程。我们已经拥有了一幅地图和一枚罗盘,这使我们能够理解正在塑造我们技术世界的基本力量之一。
本文由 @Faye. 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来源于Unsplash,遵循CC0协议

Please specify source if reproduced揭秘AI大模型训练中的“学习率”秘密:万字深度解析 | AI工具导航