

为确保高考的公正性,国内一些知名AI大模型,如腾讯混元、通义千问、Kimi和豆包等,决定在今年高考期间暂停其图片识别及问答功能。小雷对此表示质疑,认为这或许过于高估了这些AI大模型的实际水平,因为他之前测试过,这些AI在解答高考题时的表现并不理想。
截止目前,2025年高考全国一卷的语文、英语和数学试卷已公开。其中,语文试卷的内容被多家媒体进行了实测,AI大模型在写作部分的表现也被广泛关注。然而,关于这些AI生成的文章质量,存在不同的看法。小雷注意到,评测中大多数文章只是简单展示了AI生成的内容,并未附带详细点评,最终的质量需要读者自行判断。
(图源:百度搜索截图)
为了更好地评估AI的表现,小雷选择了数学科目,它有明确的标准答案,并对几款AI大模型进行了测试,具体包括DeepSeek、豆包、讯飞星火、文心一言、Kimi和通义千问。这些模型能否在985、211高校中脱颖而出呢?
六款AI大模型较量,谁能成为高考的佼佼者?
接下来,先介绍一下测试的环境和题目。由于部分AI大模型无法手动切换联网功能,因此所有模型均启用了联网搜索,并且深度思考功能也全部开启。
所选数学题包含一题选择题、一题多选题、一道填空题以及一题简答题,最终将依据题目的分数进行评分。
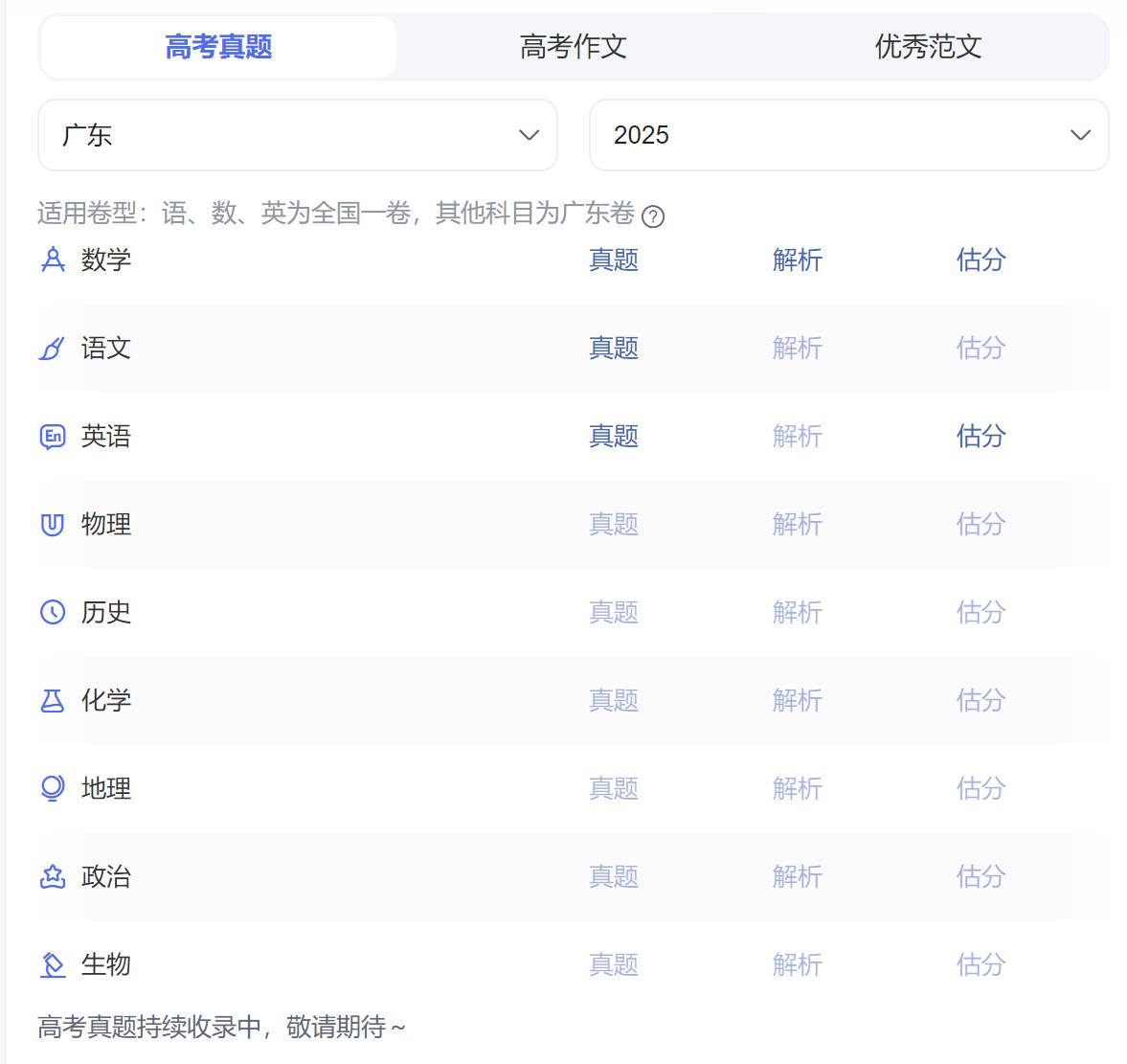
第一道题(5分):
若双曲线C的虚轴长是实轴长的√7倍,则C的离心率为(正确答案:D)
A:√6 B:2 C:√7 D:2√2
这一题可以视为热身,难度较低,参与测试的六款AI大模型均表现出色,成功计算出正确答案,并提供了详细的推理过程。在本次测试中,所有模型都获得了满分5分。(图片从左到右依次为:DeepSeek、讯飞星火、豆包、Kimi、文心一言、通义千问,下图同)
(图源:App截图)
虽然这道题的难度不算很高,但六款AI模型的表现让小雷感到非常惊艳。在以往的测试中,这些AI模型在面对稍微复杂的问题时,往往难以得出准确的答案。
仅经过一次测试,DeepSeek、讯飞星火、豆包、文心一言、Kimi和通义千问这六款AI模型便展现了它们的实力,甚至可能被高考生用于作弊,因此暂停其图片识别问答功能绝不是为了吸引高考的关注。
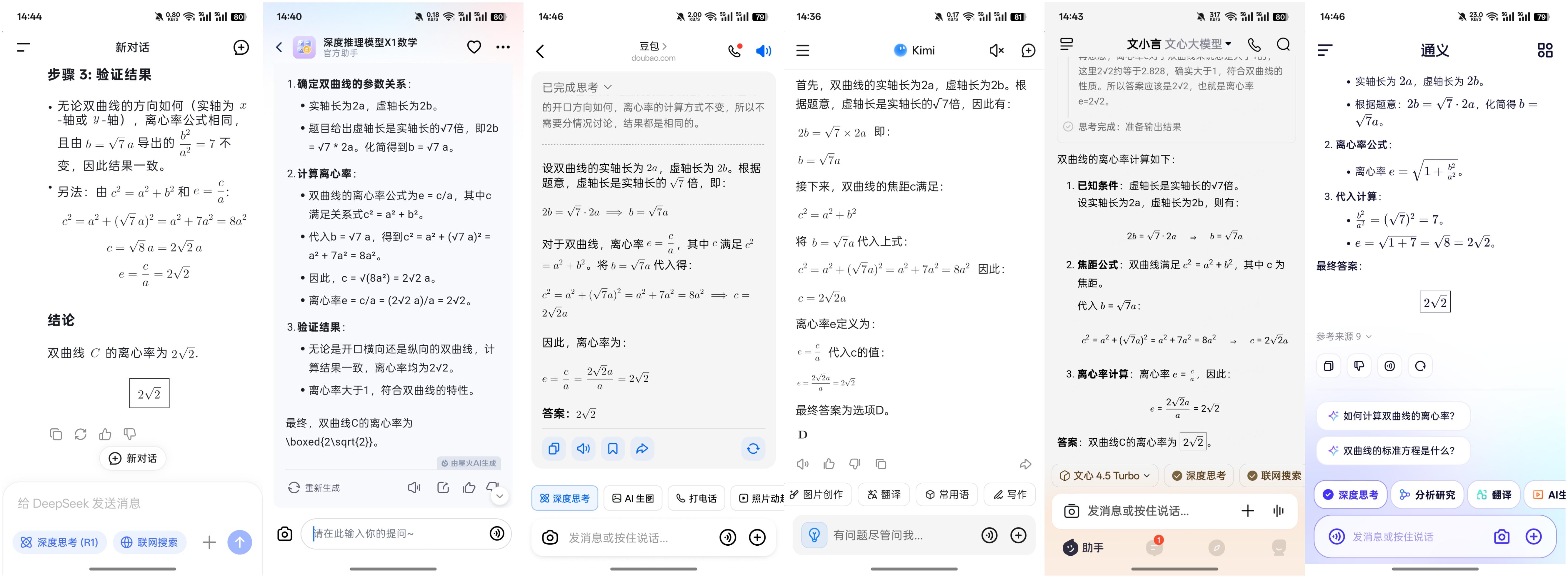
第二题(6分):
已知cos 2A+cos 2B+2sin C=2,SΔABC=1/4,cos Acos Bsin C=1/4,则(正确答案:ACD)
A:sin C=sin²A+sin²B B:AC²+BC²=3 C:AB=√2 D:sin A+sin B=(√6)/2
这道题的难度相对较高,只有豆包在两分钟内找到了正确答案,讯飞星火和通义千问则稍微耗时长一些,其他几款AI模型的计算时间更长,尤其是DeepSeek,竟然花了572秒,接近十分钟。
(图源:App截图)
假如AI模型像考生那样每次只解一道题,推理较慢的三款AI模型可能在两小时内无法完成所有题目。
尽管所有AI模型在本次测试中都成功回答了问题,但从推理所需的时间来看,豆包、讯飞星火和通义千问的表现相对较为优秀。
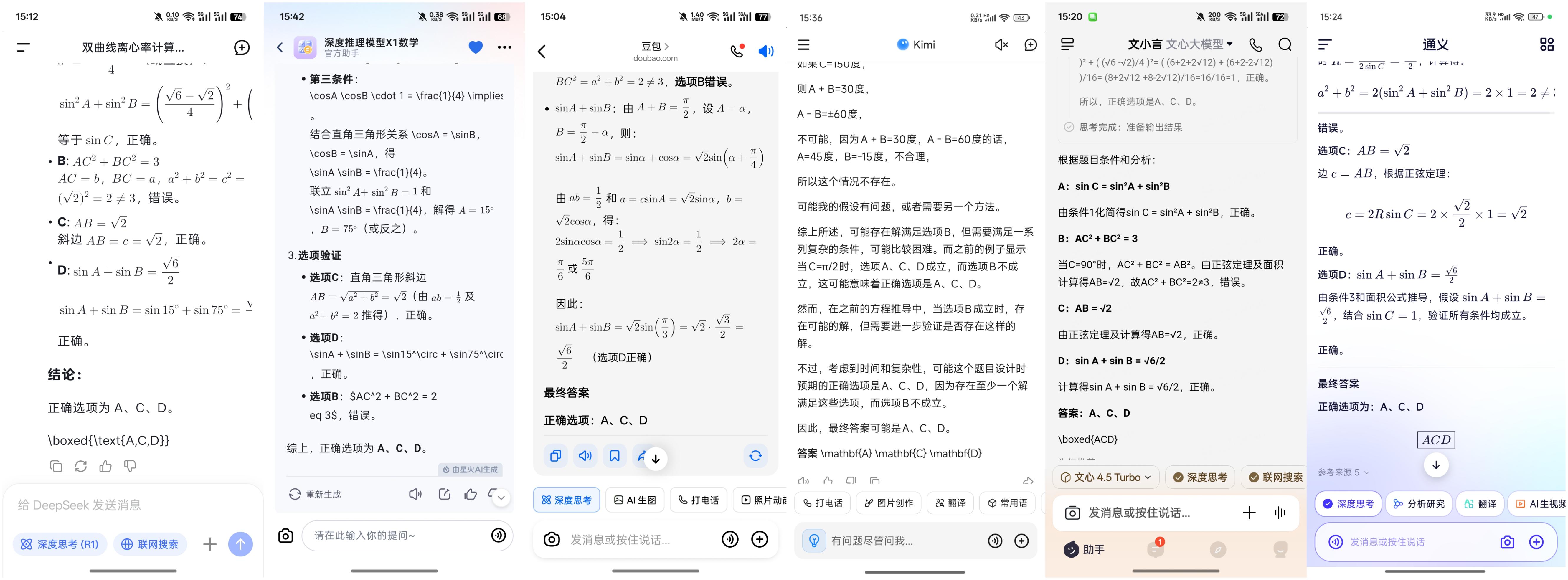
第三题(5分):
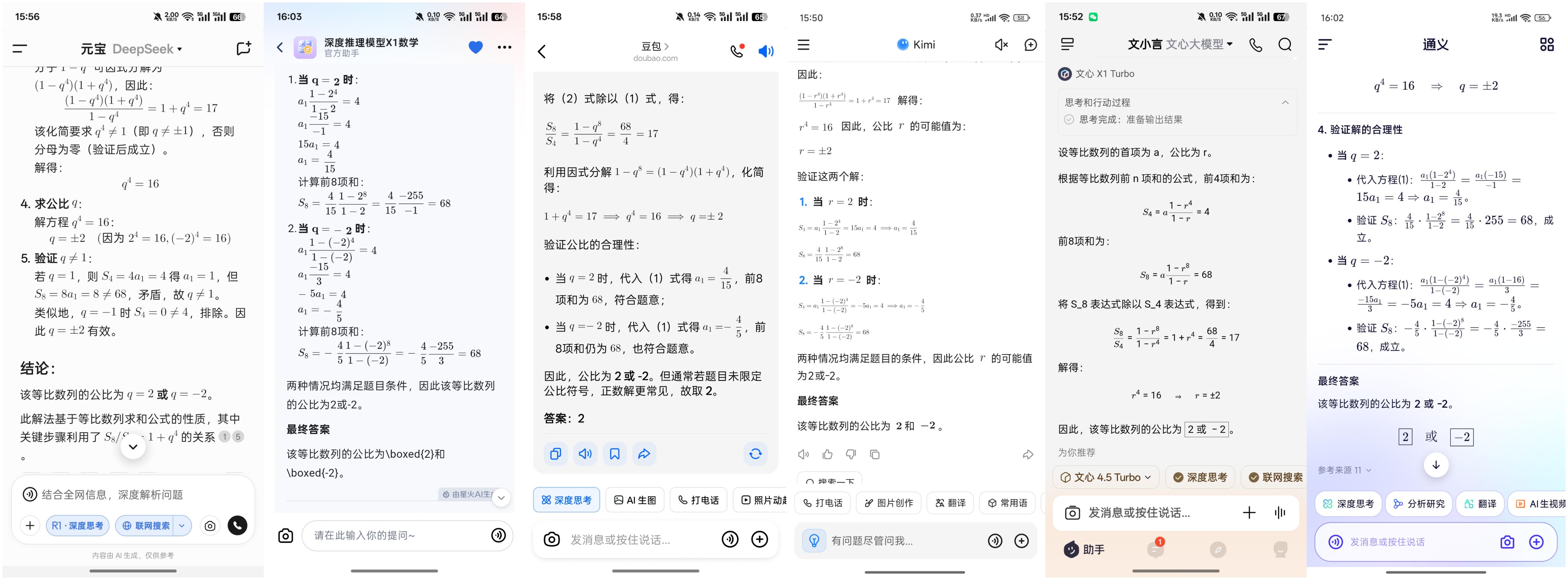
若一个等比数列的前4项和为4,前8项和为68,则该等比数列的公比为(正确答案:±2)
与前一题相比,这一题的难度有所降低,讯飞星火、文心一言、Kimi、通义千问和DeepSeek五款大模型都迅速得出了正确答案,其中文心一言几乎是瞬间完成。尽管豆包也计算出了正确答案,但在输出时却出现了错误,排除了-2,因此小雷不得不给豆包扣去三分,该题豆包的得分只能是2分。
AI大模型能力大比拼,成绩差距显著
(图源:App截图)
在本次测试中,DeepSeek的服务器经常出现繁忙的情况,导致小雷不得不借助其他应用来完成测试。幸运的是,现阶段许多AI工具都已与DeepSeek接口对接,小雷所使用的腾讯元宝App,在推理速度和稳定性上,明显优于DeepSeek的网页版和App版本。
第四题(17分):
设数列{an}满足a₁=3,(an+1)/n=(an/(n+1))+(1/(n(n+1)))
(1)证明:{n an}是等差数列;(正确答案为:n an是an=3,公差为1的等差数列)
(2)设f(x)=a₁X+a₂X²+a₃X³+...+amX^m,求f′(-2)。(正确答案为:f′(-2)=(7/9)-((3m+7)/9)·(-2^m))
在前三道题中,各大AI应用的表现差别不大,能力基本相当。而第四题的复杂性显著增加,成为检验AI大模型能力的重要挑战。
在本轮测试中,豆包、讯飞星火、Kimi、文心一言和DeepSeek依然表现出色,成功计算出两道题的答案。相比之下,通义千问在解答时,虽然能够推导出第一小题的结果,但第二小题却出现了错误,表现稍显逊色。
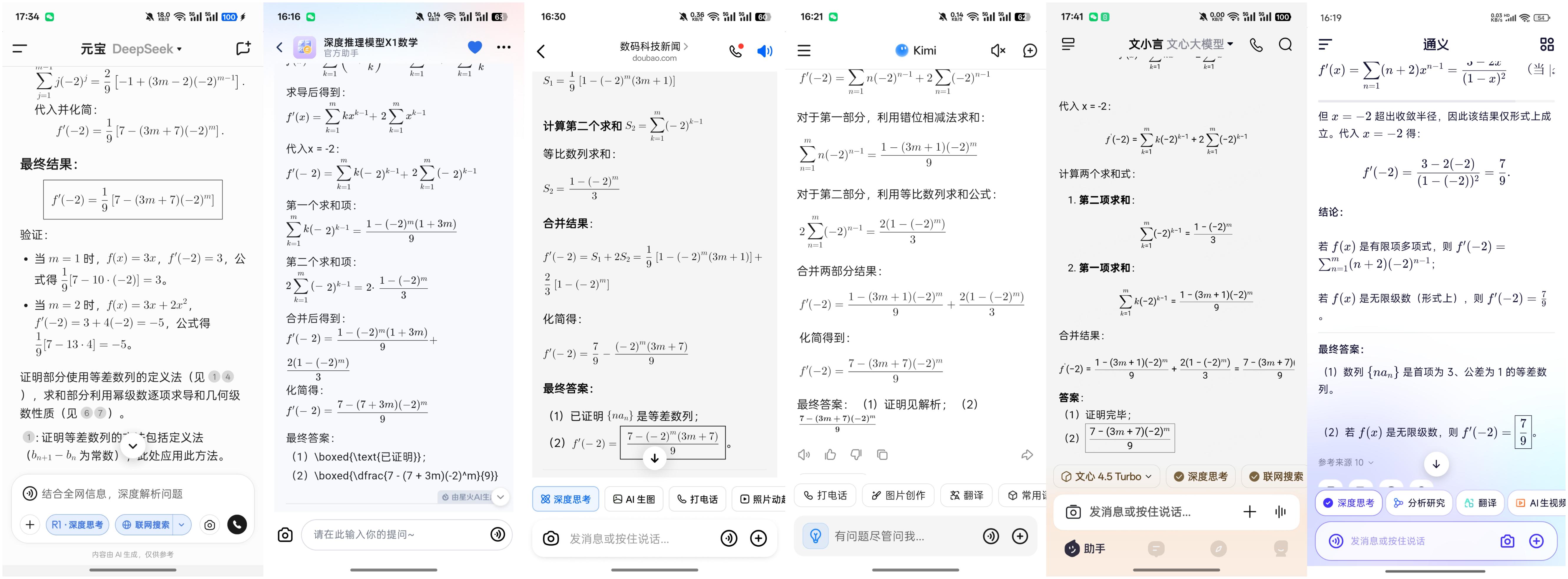
(图源:App截图)
在本次测试中,豆包、讯飞星火、文心一言、Kimi和DeepSeek均获得了满分17分,而通义千问因第二道小题的错误,仅得7分。
通过公式与逻辑推理的数学题似乎更符合AI的特性,但往年的评测中,AI大模型在阅读理解和写作方面的表现更为突出,面对复杂数学题时常常束手无策。
根据光明网去年6月的报道,复旦大学的NLP实验结果显示,AI大模型在应对2024年高考题时,语文领域的表现远胜于数学,甚至在一些数学题中全军覆没,未能正确解答,尤其是在多选题中错误频出。究其原因在于,数学题的精确性要求极高,丝毫不能出错,而文史类题目则相对宽松,允许部分模糊和错误的答案。
经过一年的发展,AI大模型取得了显著进步,深度思考模式和针对数学题的专门优化,使其在处理高考数学题时更加得心应手。
四道题目的测试结果如下:
- DeepSeek:33分;
- 讯飞星火:33分;
- 豆包:30分;
- Kimi:33分;
- 文心一言:33分;
- 通义千问:23分。
AI大模型的崛起:高考数学题的挑战与应对
通过测试,我们发现DeepSeek、讯飞星火、Kimi和文心一言均实现了满分的佳绩。豆包由于一时的失误,遗憾地丢掉了三分,未能成为高考状元。尽管通义千问在解决简单问题时表现出色,但在处理复杂数学题时却存在计算错误,需要进一步提升。

(图源:豆包AI生成)
苹果公司一向对AI行业持怀疑态度,最近在一篇论文中指出AI推理模型不过是“假思考”,缺乏稳定和可理解的推理过程,更多地像是记忆的简单复述,面对复杂任务时可能会出现崩溃现象。AI研究者Lisan al Gaib复现了苹果的测试方法,认为问题并不在于模型的推理能力,而是由于苹果对输出token的限制。
尽管AI大模型的推理能力可能仍有局限,但它们的进步是显而易见的。去年的复旦大学NLP实验室对AI大模型的测试中,面对高考数学题的表现令人失望,而在今年的评测中,这些模型几乎都能准确计算出题目的答案,曾经困扰它们的多选题如今也不再是问题。
AI大模型在数学题解答能力上的提升,最受益的恐怕是广大学生。国内的学习设备制造商和教育辅导平台纷纷开始引入AI答题功能,但当前许多设备的AI大模型仅能处理中小学的题目,例如行业领先的小猿搜题,其题库内并未涵盖大学课程。
这六款AI大模型的突出表现,彰显了国内顶尖AI企业的实力。高考数学题已被成功攻克,而高等数学的挑战也不再遥远。学习机制造商和教育辅导平台可以与领先的AI企业合作,进一步提升产品的AI答题能力,继续加强AI在教育硬件领域的应用。
夏日的阳光灿烂,正是金榜题名的时刻。
又到了一年高考季,雷科技推出“高考毕业季”专题,旨在满足学生粉丝的信息需求,涵盖搜索、AI工具推荐及手机、PC等产品的选购建议。
敬请期待!


Please specify source if reproduced六大AI大模型高考数学对决:揭开AI界“状元”的惊人秘密! | AI工具导航