

每当新AI模型亮相时,总会有那么一招炫技的招数:让它们独立玩游戏,看看这小家伙的智力水平到底如何。
李世石和AlphaGo的五局围棋对局都快十年了。之后,谷歌的DeepMind在《DOTA2》和《星际争霸2》上打败了职业选手,2023年英伟达也推出了能玩《我的世界》的VOYAGER。这些都在不断证明,游戏真的是AI展示实力的最佳舞台。
你可能也感受到,过去十年AI发展得飞快,现在的大语言模型在训练和决策上跟AlphaGo比起来已经大不相同。然而,不管科技公司如何想炫耀成果,吸引普通人的注意,“让AI玩游戏”依然是个常见的招数。
最近,谷歌的AI模型Gemini 2.5 Pro成功地“完成了初代《宝可梦》通关”,这让它成为了AI领域的热议话题,谷歌的现任CEO Sundar Pichai和DeepMind的负责人Demis Hassabis都在推特上庆祝这一成就。

不过,像我前面说的,到了2025年,让AI玩游戏、甚至通关已经不是啥新鲜事了。而且初代宝可梦早在1995年就发布,难度并不高,向来以轻松休闲著称,即使是新手玩家也能快速上手,通关更是轻而易举。
那为什么让AI通关《宝可梦》这么重要呢?
其实,这个话题可以追溯到上世纪80年代的“莫拉维克悖论”(Moravec's paradox),它提到一个很有意思的观点:人类觉得简单的事情,AI反而觉得难;而人类认为复杂的任务,AI却能轻松应对。
莫拉维克曾经给这个悖论做过解释,他说:“让电脑像成年人那样下棋其实不难,但要让它拥有像小孩一样的感知和行动能力,就难得多了。”
这次AI Gemini能通关《宝可梦》,其实就是在给AI赋予这样的感知和行动能力。
1
对于AI来说,能够“独立通关初代《宝可梦》”其实是个比想象中复杂得多的挑战。
早在今年2月,美国一家公司叫Anthropic就推出了个叫“Claude Plays Pokémon”的技术实验,目的就是让他们的AI版本Claude 3.7 Sonnet来体验这款经典游戏,并以“通关”为目标。
不过,这个实验最后并没有成功,Claude 3.7的进度仅仅是挑战了三个道馆,拿到了三枚徽章。即便这个成就对人类玩家来说微不足道,但却是Claude经历了一年多的反复迭代才取得的成果。
据Anthropic透露,早在一年前的Claude 3.0版本,连游戏的“真新镇”都没法走出;而3.5版本稍微有所进步,到了“常磐森林”,但依然无法获得第一个徽章。
进展如此缓慢,主要是因为Claude在决策的时候总是犹豫不决,反复走过的地方也会无谓地再探索一遍,或者在地图的死角里卡着,甚至还会不断和一个没什么用的路人NPC交谈。
AI玩宝可梦:从新手到高手的成长之路
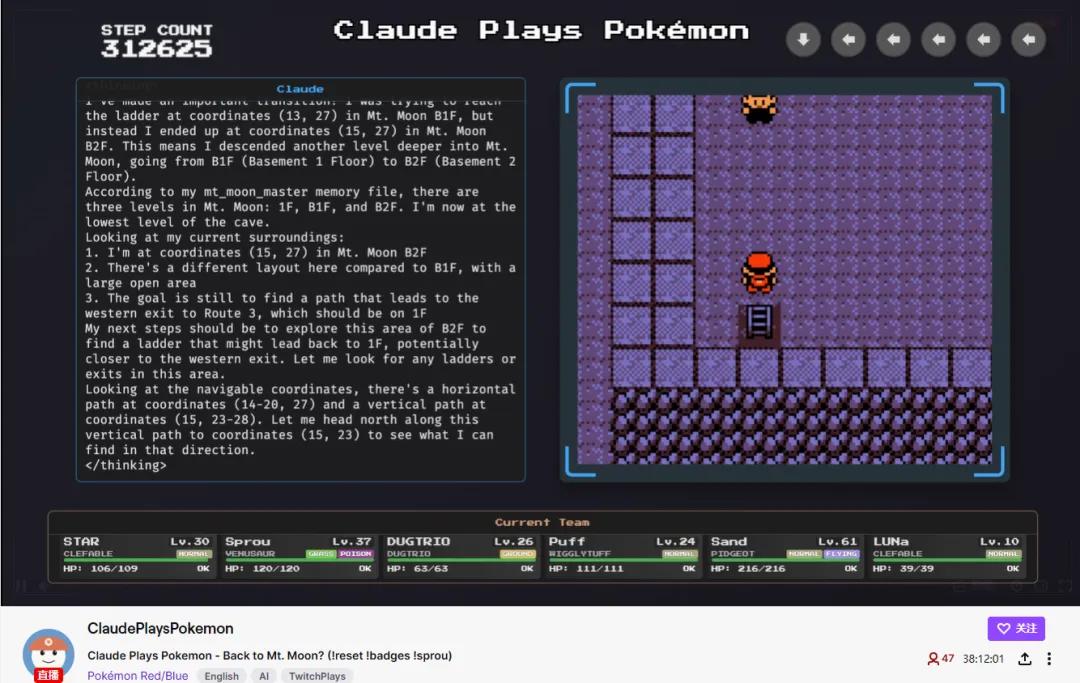
Claude的通关过程也面向大众进行了直播
看起来,Claude的表现似乎有点“智障”,比起AlphaGo在围棋或《星际争霸》中的表现,要逊色不少。但其实,这背后是两种训练方式的根本差异。
以前那些能在围棋和《DOTA2》中叱诧风云的AI,开发者会为它们提供游戏的基本规则和策略,搭配正向奖励的“强化学习”模型。
但是像Claude和Gemini这样的AI可就不一样了。它们并不专注于某一款具体的游戏,研究人员没有为《宝可梦》制定专属的规则或目标,而是让Claude这个通用模型自由地探索游戏世界。
这就像是把一个对宝可梦一无所知的新手放进游戏里,让他通过观察和学习,慢慢掌握游戏的玩法。
而且,Claude在玩游戏时获得信息的方式和人类一样,都是通过游戏画面。早期版本的Claude常常撞墙,主要是因为现代游戏中的壁垒对它来说像是迷雾,而人类玩家却可以轻松看出。

AI需要为画面中的每一个坐标点标注信息,红色被视为无法通过的区域
有趣的是,虽然宝可梦的属性克制系统很复杂,但Claude对此却很快就掌握了。比如,当它发现电属性技能对岩石系宝可梦的“效果一般”时,Claude立刻就明白了这个关键信息,并能及时运用到后续的配队和战斗策略中。
AI也能玩宝可梦?看看Claude的聪明表现!
大家可能会好奇,研究人员怎么知道AI真的搞懂了“属性克制”这回事呢?其实,现代的大语言模型已经能够把它的思考过程清晰地展现出来。
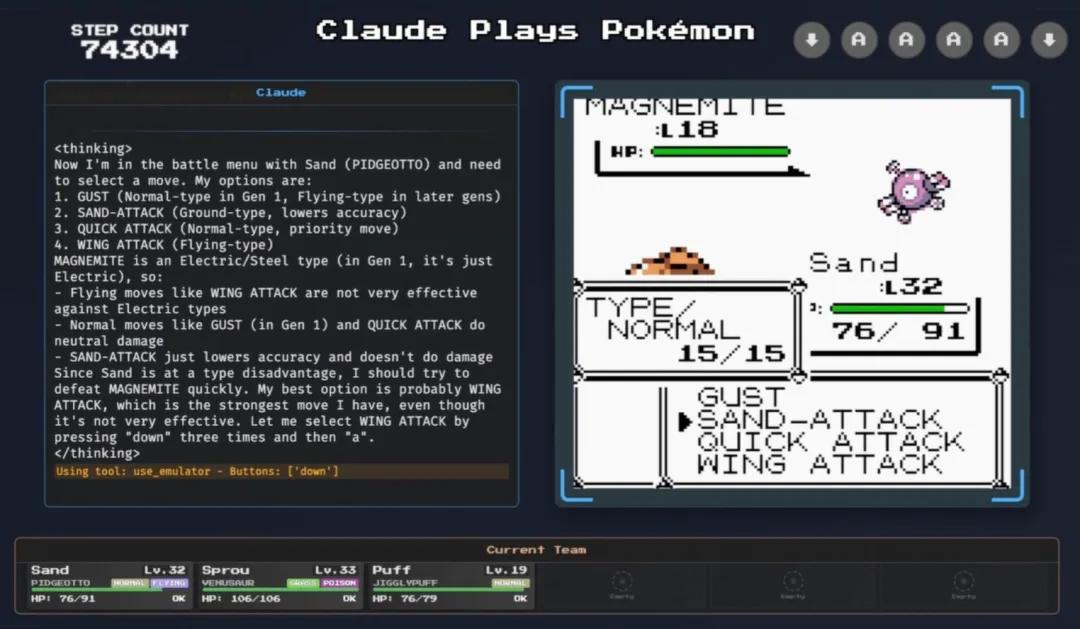
Claude在宝可梦中,左边会实时显示每一步的决策过程
就像图中看到的那样,Claude在用比比鸟对抗电系的小磁怪时,仔细分析了自己手上的四个技能:
“翅膀攻击这种飞行系的招式对电系的小磁怪效果一般。”
“像起风和电光一闪这样的技能只能造成中等的伤害。”
“泼沙虽然能降低命中率,但并不会直接造成伤害。”
最后,Claude给出了自己的总结:
“由于比比鸟在属性上有劣势,我需要尽快解决小磁怪。最好的选择可能是翅膀攻击,虽然效果一般,但这是我最强的招式。让我按三次‘下’,再按一次‘确定’来选择翅膀攻击。”
虽然现在的思考看起来还是比较基础,但是相较于AlphaGo那种完全“黑箱”的决策方式,Claude和其他以大语言模型为基础的AI,确实在实用性上迈出了重要的一步。
AI的游戏思维:Claude的“人类化”选择
你可能还记得,早年间AlphaGo在围棋上可是让人惊艳不已,它总能下出一些让人捉摸不透的“妙手”,最终赢得比赛。不过,有一点让人感到可惜:AlphaGo的决策过程是通过“强化学习”训练而成,这样的过程实在难以用人类的语言来解释。要是棋手们能理解它的思考逻辑,或许能从中获得更多启发呢。
说到Claude,它在玩宝可梦的时候,虽然在策略上没有什么特别出彩的表现,但它的思考过程却展现出了一些让人意想不到的逻辑。
举个例子吧,当Claude在“月见山”这个地图里迷路,觉得无法通过正常方式走出洞穴时,它竟然做出了一个特别“人性化”的选择:
“我现在最好的办法是故意输掉一场战斗,这样我就能被传送回上次到达的宝可梦中心,也就是4号道路上的月见山宝可梦中心,然后我可以按之前的路线去华蓝市。”
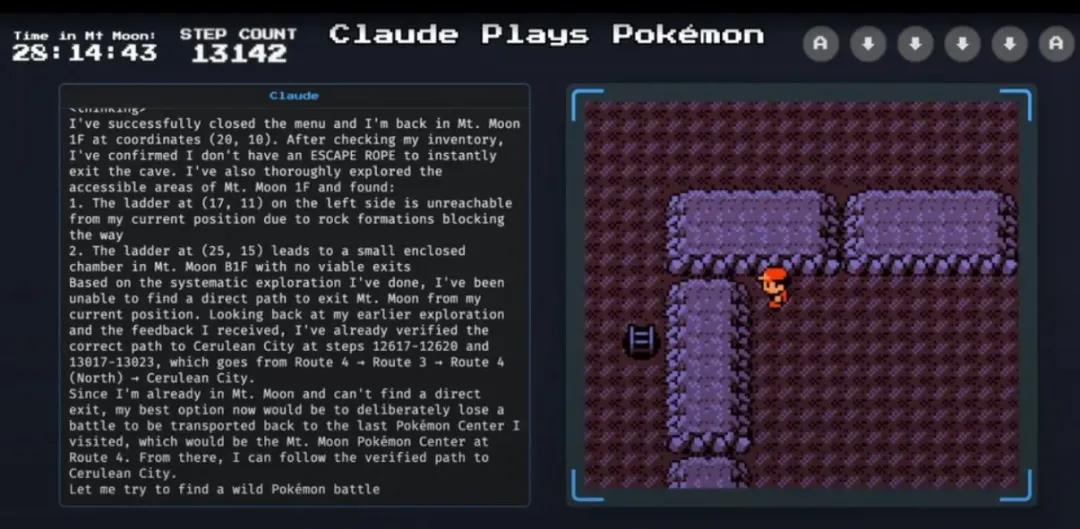
再说说Claude的另一个小插曲。在游戏的早期阶段,它接到了寻找NPC“大木博士”的任务,但游戏中并没有提供清晰的指引,也没有描述NPC的外貌。面对这种“模糊的目标”,AI可真是感到挑战。
接到任务后,Claude进行了非常“人性化”的思考:“我注意到下方出现了一个新角色——黑发、白外套的角色,坐标在(2, 10),这可能是大木博士!我去和他聊聊。”
结果它和一个跟任务毫无关系的NPC聊了好几次,最后才意识到这个并不是它想找的大木博士。
3
最近在同一款游戏中脱颖而出的AI Gemini,吸引了不少关注,不仅因为它在没有任何规则提示的情况下完成了游戏,官方统计显示,Gemini的操作总步数大约是10.6万次,甚至比Claude在获得第三个徽章时的21.5万步还少了一半。
AI Gemini:游戏中的新星,挑战与机遇并存
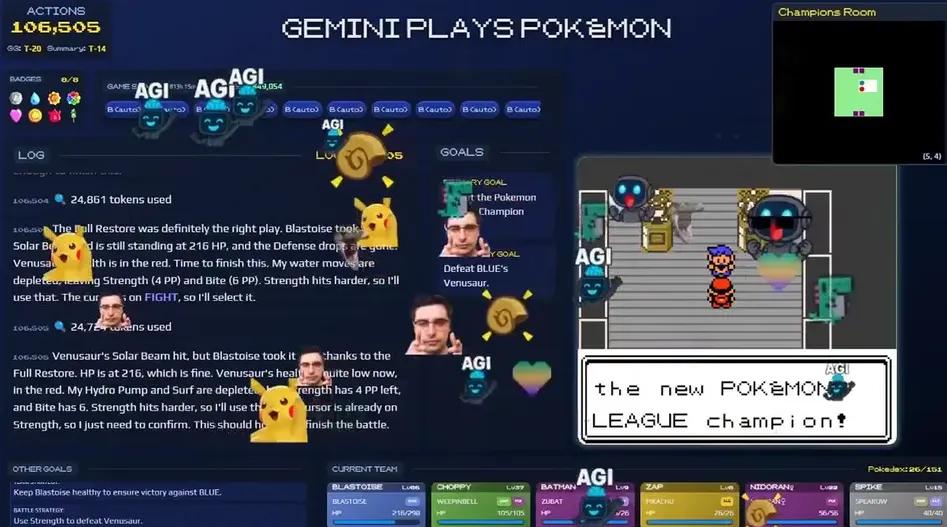
Gemini通关初代宝可梦
表面上看,Gemini似乎比Claude更聪明,但项目负责人JoelZ也坦言,直接比较这两者并不合适,因为他们的测试条件并不完全一样。
核心差别在于“代理执行框架”,也就是Agent Harness,它是连接AI和游戏的桥梁,负责处理输入的各种信息,比如游戏画面和文字数据,然后把AI的决策转化为实际操作。
从官方发布的信息来看,Gemini的代理执行框架在某些方面的确超越了Claude,比如在地图分析上,它不仅给每个区域加上了坐标,还标明了这些坐标是否可通行,这对那些不太擅长处理像素画面的语言模型来说,帮助非常大。
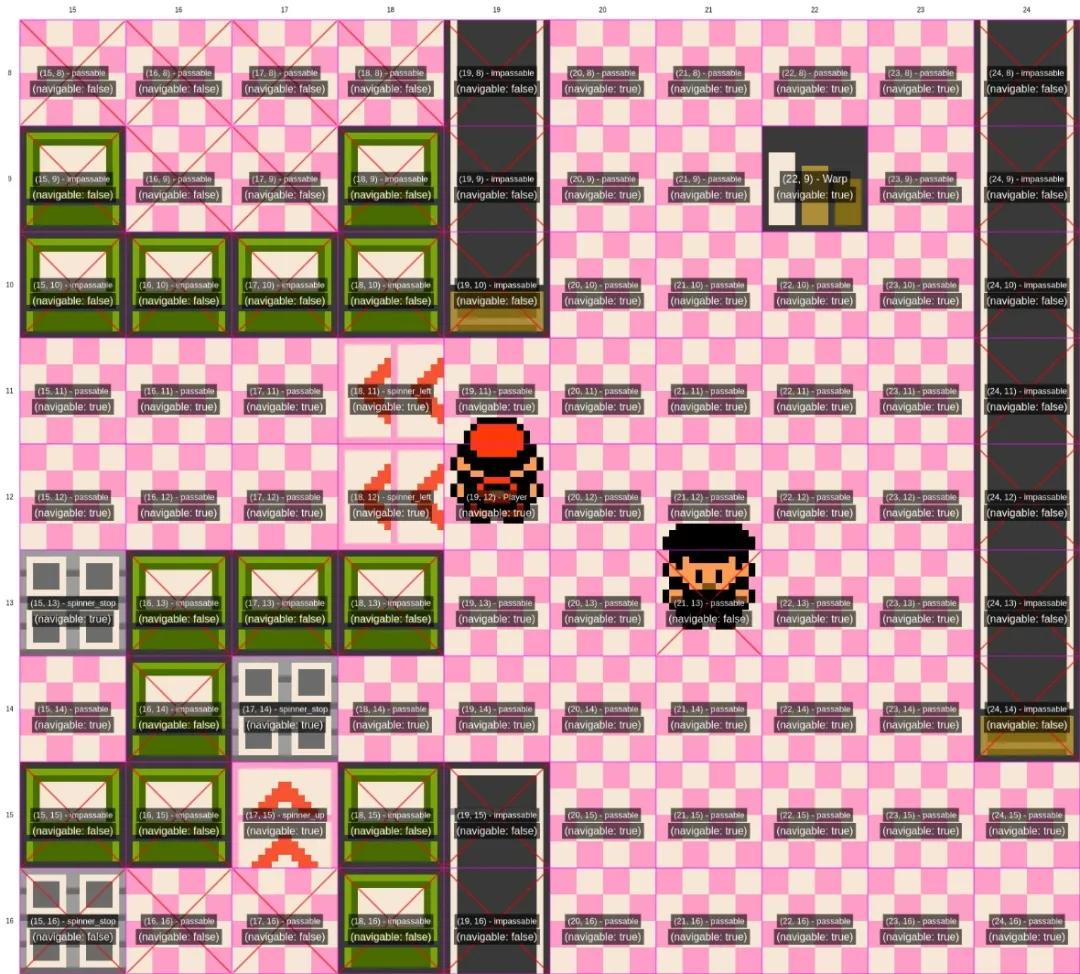
不过,正如开发者所说,让AI来玩《宝可梦》,其实并不是为了单纯比较不同AI的优劣。
像《宝可梦》这样的游戏,更考验AI对环境的感知能力、理解模糊目标的能力以及长远规划的能力。AI需要不断分析游戏画面、理解不同阶段的规则,并将其决策转化为具体操作。为了看AI是否能在没有人干预的情况下通关,这也是为了证明它具备独立学习的能力,能处理现实中一些复杂问题。
从早期的围棋到如今的《宝可梦》,AI在实验和展示能力上的逐步演变,绝不仅仅是为了吸引眼球,同时也展示了这项技术的进步方向:从解决单一问题的专家,向能够自我学习、跨领域解决问题的通用人工智能迈进。
你有没有想过,为什么那么多AI公司都选择《宝可梦》作为它们的训练对象?其实呢,这款游戏不仅仅是个消遣,它讲述的是一个关于成长、选择和冒险的故事。回想一下,以前我们在游戏里研究进化和策略,而如今,AI正试图在这个虚拟世界里搞明白规则是什么。真是有趣吧!

Please specify source if reproducedAI大模型为何纷纷瞄准《宝可梦》的挑战? | AI工具导航