
最近,阿里巴巴推出了Qwen3的新型模型。从数值上看,该模型不仅超越了DeepSeek,还领先于众多其他大型模型,但它的实际表现如何呢?接下来,我们将分析作者的见解。
 一、基础介绍
一、基础介绍
在经历了claude 3.7、Gemini 2.5和GPT 4.1的发布后,通义千问于4月29日正式推出了Qwen3系列模型。这一系列的模型不仅在硬件成本上仅为DeepSeek R1的三分之一,而且在性能上实现了全面的超越,甚至与全球领先的Gemini 2.5 Pro相媲美,同时还具备了mcp能力。此外,Qwen3-30B-A3B这一小型MoE(混合专家模型)具有的激活参数数量仅为QwQ-32B的10%。即便是像Qwen3-4B这样的小型模型,其性能也能与Qwen2.5-72B-Instruct相抗衡。


Qwen3系列模型包括六种不同规格,参数量从最小的0.6B到最大的235B-A22B,能够满足从移动端到企业级应用的多样化需求。旗舰型号Qwen3-235B-A22B的“235B-A22B”标识代表该模型的总参数量达到2350亿,每次推理仅激活220亿参数,展现出在数学推理、编程及对话方面远超DeepSeek R1的能力,接近Gemini 2.5 Pro的水平。
Qwen3系列的八款模型已全面开源,包括六款稠密(Dense)模型和两款MoE模型。

多种思考模式
值得关注的是,Qwen3具备两种不同的思考模式:
- 在推理模式下,模型展示了思考的过程,虽然响应时间较长,但在处理复杂任务时表现得尤为出色;
- 而普通模式则省略了思考步骤,能够迅速响应,更适合日常对话及长文本的创作。
灵活思考与多语言能力的结合
这种灵活性使得用户可以根据特定任务的需求,掌控模型的“思考”程度。例如,对于复杂的问题,用户能够通过增加推理步骤来进行深入分析,而简单问题则可迅速得到答案,无需过多等待。
更为重要的是,这两种思考模式的结合极大地提升了模型在“思考预算”方面的稳定性与效率。
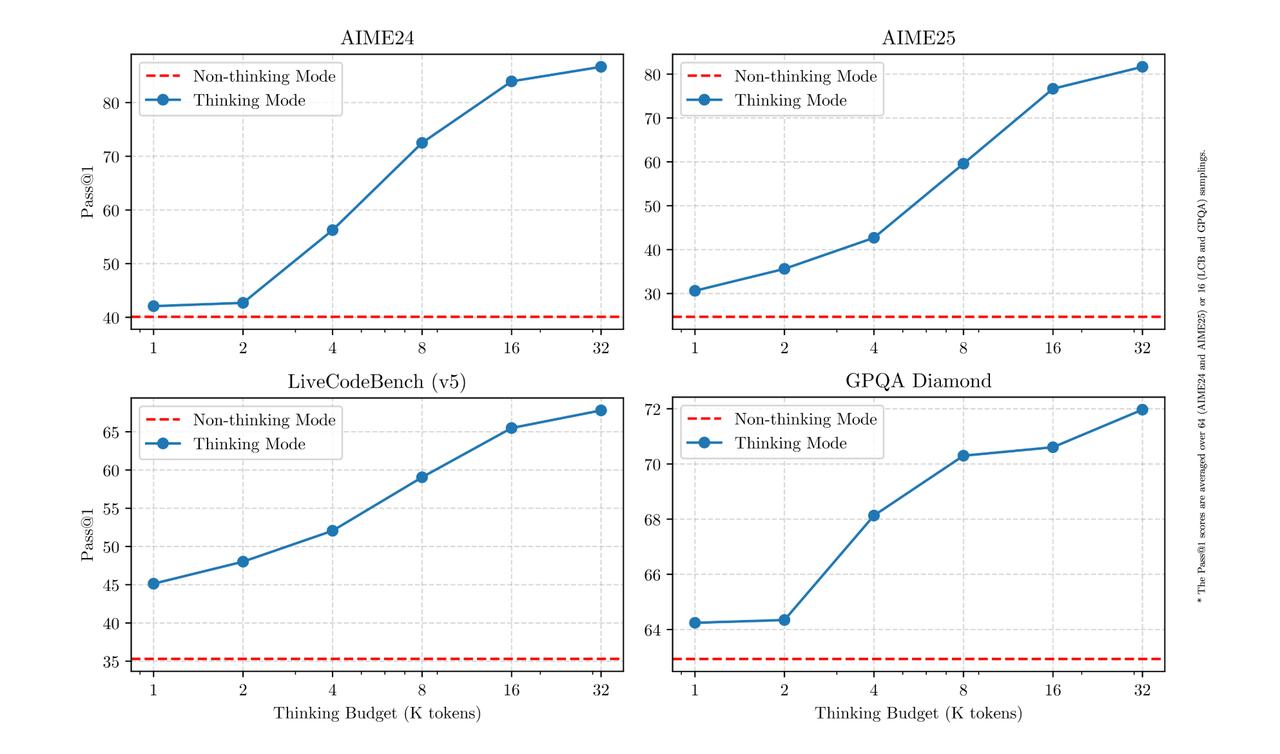
广泛的多语言支持
与此同时,Qwen3 模型能够支持119种语言和方言,这种广泛的多语种能力为国际应用开辟了新的机会,使得全球用户都能享受到模型的强大功能。

Agent能力的显著提升
此外,该系列模型在MCP能力方面进行了显著升级,能够精准识别外部函数,并支持多种工具的灵活调用与串联,为Agent的开发提供了强有力的支持。
部署优势分析
在部署成本方面,Qwen3-235B-A22B展现出显著的优势。作为一种稀疏的Mixture-of-Experts(MoE)架构,其硬件资源消耗显著低于同等规模的密集模型。得益于高效的设计和FP8精度权重的支持,Qwen3-235B-A22B可在仅需4张H20或H800显卡上高效推理,显著降低了推理成本与能耗。
对比之下,DeepSeek R1采用的密集架构在部署时需消耗高达1300GB的显存资源,通常需要双节点与8张A100显卡协同工作,整体硬件开销约为Qwen3的三倍。
此外,Qwen3-235B-A22B还支持通过Quick Transformers框架实现CPU与GPU的混合推理,进一步压缩了硬件开支,提升了灵活性与适配性。这些优势使其成为当前企业级大模型应用的理想选择,兼具卓越的性能与性价比。
技术训练深度解析
在技术训练方面,Qwen3借鉴了DeepSeek R1的强化学习后训练流程,对235B-A22B和32B两款大模型进行了四个阶段的复杂训练。具体包括:
- 长思维链的冷启动
- 长思维链的强化学习
- 思维模式的融合
- 通用强化学习
这一系列训练不仅显著提升了推理能力,也实现了普通问答和推理模式的智能切换,进一步增强了文本生成的能力。
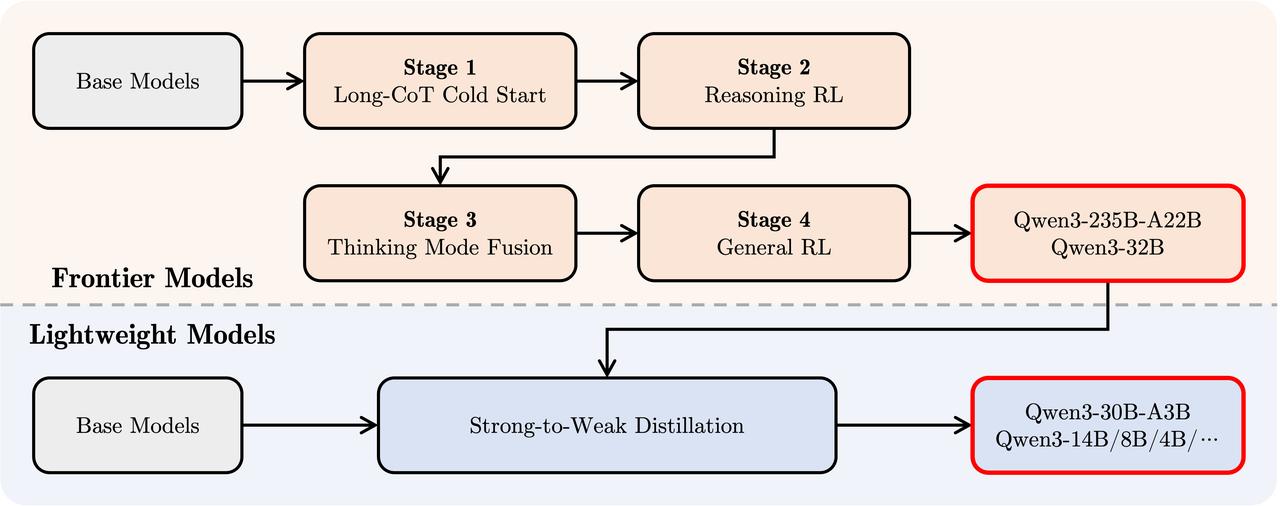
随后,团队采用模型蒸馏的方法,使用大模型生成的数据集来优化小型预训练模型。与DeepSeek R1使用Llama等外部模型不同,Qwen3的小型模型均基于原生训练的Qwen3大模型,训练流程经过进一步优化,为开源模型的发展提供了极具参考价值的经验。
案例分析
1、代码生成与理解
我选择了LeetCode中一道难度为【hard】的代码题进行测试。
结论:测试结果显示其代码能力出众,表现非常优秀。
2、动态网页生成能力
请基于以下要求设计一个HTML动态广告网页:
1. 采用扁平化设计风格,背景颜色应为浅色,与#0FB990和#101010相近的颜色作高亮展示。
2. 背景中使用淡网格线,以增强科技感。
3. 突出核心要点,使用超大字体或显眼的视觉元素,形成小元素的鲜明对比。
4. 中英文结合,大字体中文作为主要展示,英文小字作为辅助信息。
5. 通过简洁的线条图形化呈现数据或作为配图元素。
6. 利用高亮及透明度渐变,营造科技氛围,注意不同高亮色之间不应互相渐变。
7. 模仿Apple官网的动效,实现鼠标向下滑动时的流畅效果。
结论:虽然整体设计显得简洁,但效果依然令人满意,经过后续调整后可用于实际应用。
3、遵循指令的能力
请按照以下步骤进行操作:首先,构思一句正好10个字的中文句子。接着,将句中的每个汉字转换为对应的拼音(不带声调)。最后,将转换后的拼音结果进行倒序排列。请确保严格按照要求完成。
评分标准:
- 句子要求:提供的句子必须恰好为10个汉字,且语法通顺,符合逻辑。
- 拼音转换:准确转换每个汉字为拼音,拼写无误且不含声调。
- 倒序输出:将拼音完全反转,顺序无遗漏或多余字符。
- 格式要求:各拼音之间分隔清晰,使用空格分隔,无附加说明。
- 指令遵循:严格按照三个步骤执行,无省略或额外步骤,最终答案符合所有要求。
结论:此回答的质量较低,远未达到我们的预期。
4、逻辑推理能力
揭开真相:谁是钻石失窃案的罪魁祸首?
在一起钻石失窃事件中,警方对三名嫌疑人甲、乙、丙展开调查,认为其中一人可能是窃贼。每个人的陈述如下:甲声称:“小偷是乙。” 乙则表示:“小偷是丙。” 而丙的说法是:“小偷是乙。” 根据已知条件,这三人中仅有一人说了真话。我们需要通过推理找出真正的小偷。
首先,假设甲说的是真话,即乙是小偷。那么根据这一假设,乙和丙的陈述必然为假。乙说小偷是丙,这与甲的说法相悖,丙说小偷是乙也与之矛盾,因此这种情况不成立。
接下来,我们考虑乙说的是真话,即小偷是丙。如果这一陈述为真,那么甲的说法“小偷是乙”就为假,而丙的说法“小偷是乙”也同样为假,这样就符合只有一人说真话的条件。因此,乙为真,丙为小偷的假设是合理的。
最后,我们分析丙的陈述。如果丙说的是真话,那么小偷是乙。这将导致甲的说法为假(小偷是乙),而乙的说法“小偷是丙”也变为假,这样就会出现矛盾,因为这意味着两个人的陈述都是假的,与条件不符。
因此,通过以上推理,我们可以明确得出结论:丙是钻石的真正小偷。这个推理过程不仅逻辑严谨,还清晰地展示了每一步的推导。
结论:经过分析,丙就是罪犯,推理过程合理且逻辑清晰。
通过这几个案例,我们不难发现,Qwen3的整体表现令人满意,建议大家也可以尝试使用。
总结
回首2024年,大模型领域虽然呈现出多样化的局面,但开源技术却面临瓶颈。Llama 4被指控作弊,Meta的发展遇到了阻碍;而谷歌的Gemini 3与智谱的GLM 4等开源模型大多规模较小,难以满足工业级应用的需求。
在这样的背景下,千问3系列模型的推出显得尤为重要。尽管其编号为“3”,但根据千问模型每次版本迭代0.5的规律,这实际上是该系列的第五代产品。
经过两年的打磨、五个版本的迭代以及数百款模型的优化,千问模型已经从开源领域的“新秀”成长为行业的标杆,肩负起推动全球开源大模型发展的重任,成为技术进步的中坚力量。
本文由 @贝琳_belin 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来源于Unsplash,基于CC0协议。
本文所表达的观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。

Please specify source if reproduced全面评测:深入解读最强开源AI模型Qwen3的魅力与潜力 | AI工具导航