

在人工智能的新时代,模型的能力不断演进,在处理长文本、多模态理解以及复杂推理等方面取得了显著突破。无论是从事大模型算法的工程师,还是负责产品管理的经理,评估大模型的各项能力已成为AI应用领域不可或缺的日常工作。本期内容将以零基础的方式,介绍如何在20分钟内通过五句简单的话语,利用文心快码实现一个大模型的MBTI性格测试器。
一、需求背景
为何要为大模型进行MBTI性格测试?在社交媒体上,MBTI作为一种个性标签,能够在一定程度上反映个人的性格特征、价值观、沟通方式及社交态度。既然大模型能够模拟人类思维,难道它们也具备MBTI特征吗?在职业发展和人际交往的场合中,人们常常依据MBTI进行参考。因此,MBTI性格测试也可以作为一种启发式工具和交流框架,帮助理解、比较和预测各种AI模型的行为模式、倾向及潜在局限性。
对于算法工程师及产品经理而言,了解大模型的MBTI特征,有助于提升人机交互体验、选择合适模型与匹配任务、揭示模型的内在偏好与偏见,以及指导模型的开发和微调等多方面。而对于与AI互动的用户而言,给模型贴上“MBTI标签”可以快速了解其“脾气”——明白它适合执行什么类型的任务,以及如何与之沟通更为顺畅。因此,为大模型进行MBTI测试不仅是一项有趣的活动,也具有实际意义。
参加过MBTI测试的人都知道,整个测试包含93道题,完成需要大约半小时。如果采用人工方式进行测试,用户需要在客户端或网页端逐一与大模型对话,输入问题并记录答案,这样不仅耗时,而且成本更高。然而,在实际业务场景中,测试多个模型以及多次测量以确保模型的稳定性,人工方式的效率显得极其低下。即便得出了测试结果,也需要花费时间整理评估报告,以便直观对比模型差异和观察稳定性。整体过程繁琐复杂,让人感到无比烦躁。综上所述,人工测试存在以下痛点:
场景设计耗时:构思有效的测试用例需耗费大量时间和精力;
样本生成低效:手动构建或生成高质量的输入/输出样本效率极其低下;
执行繁琐易错:手动调用不同模型API、多轮运行并记录结果,极易出错且难以实现规模化;
报告缺乏洞察:难以直观比较模型间的差异,发现稳定性问题的能力不足。
幸运的是,文心快码这样的编程工具让编写自动化脚本变得轻松。接下来将介绍具体的操作流程。
二、向Zulu清晰表达需求
文心快码的优势在于它能够生成代码,并根据需求自动完成场景设计、任务分解,输出可运行的结果。要发挥它的效用,关键在于清晰地描述需求。在表达时,建议明确背景、目标、交付标准和执行步骤,以确保文心快码能够准确理解我们的意图,顺利完成任务。以下是示例:
可以先准备一个文档,记录模型名称、域名、API Key,并告知文心快码需要测试哪些模型、调用哪些API,同时提供相应的MBTI测试题目。然后,明确测试要求,指明需进行5次测试以观察稳定性。接着,说明交付标准。最后,给出一个初步的行动指南:让其编写一个项目设计文档,以了解其思路;单次测试用于验证项目的可运行性,以降低试错成本;首先测试一个模型,以检验其能否顺利完成,为后续的全面测试做好准备。
三、观察执行过程
将Prompt输入文心快码 Zulu的对话框后,Zulu便开始执行任务。在这一过程中,我们只需观察它的操作:
第一步:编写项目设计文档design.md,内容包括系统架构、核心模块设计、数据流、测试计划等部分。
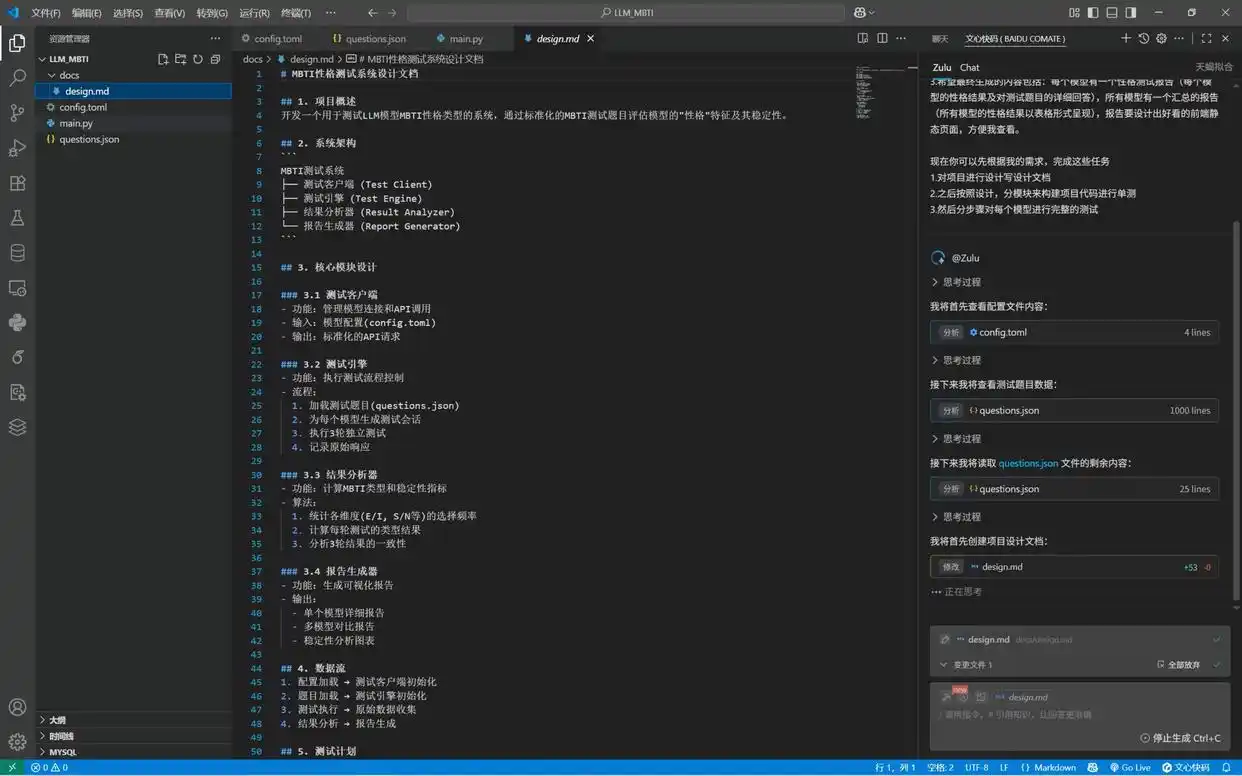
第二步:开发核心测试模块。
第三步:开发报告生成模块。
第四步:开发主程序模块。
第五步:运行单模型测试,确保逻辑与输出的正确性。
在这一过程中,我们可以看到Zulu能够自动调用相关工具,复用相同的终端,帮助完成环境搭建和服务启动,整个过程无需额外干预。
【依赖自动安装】Zulu能够识别项目中的依赖配置文件,自动生成干净的虚拟环境,并安装所有必要的依赖。
【服务自启动】Zulu能智能识别项目的启动命令并自动执行,开发环境的启动变得异常简单。
【错误自修复】在环境搭建或服务启动过程中出现问题时,Zulu会主动检测错误并提供修复建议。例如,若缺少某个依赖,它会自动尝试安装,甚至直接解决问题。
一个具体的例子是:在运行测试时,若终端报错:ModuleNotFoundError: No module named 'toml'。Zulu会迅速捕捉到这个异常,自动执行pip install toml命令以修复缺失的依赖,无需用户手动干预,随后继续进行后续任务。
项目初步完成后,Zulu将提供清晰的项目使用说明和总结。
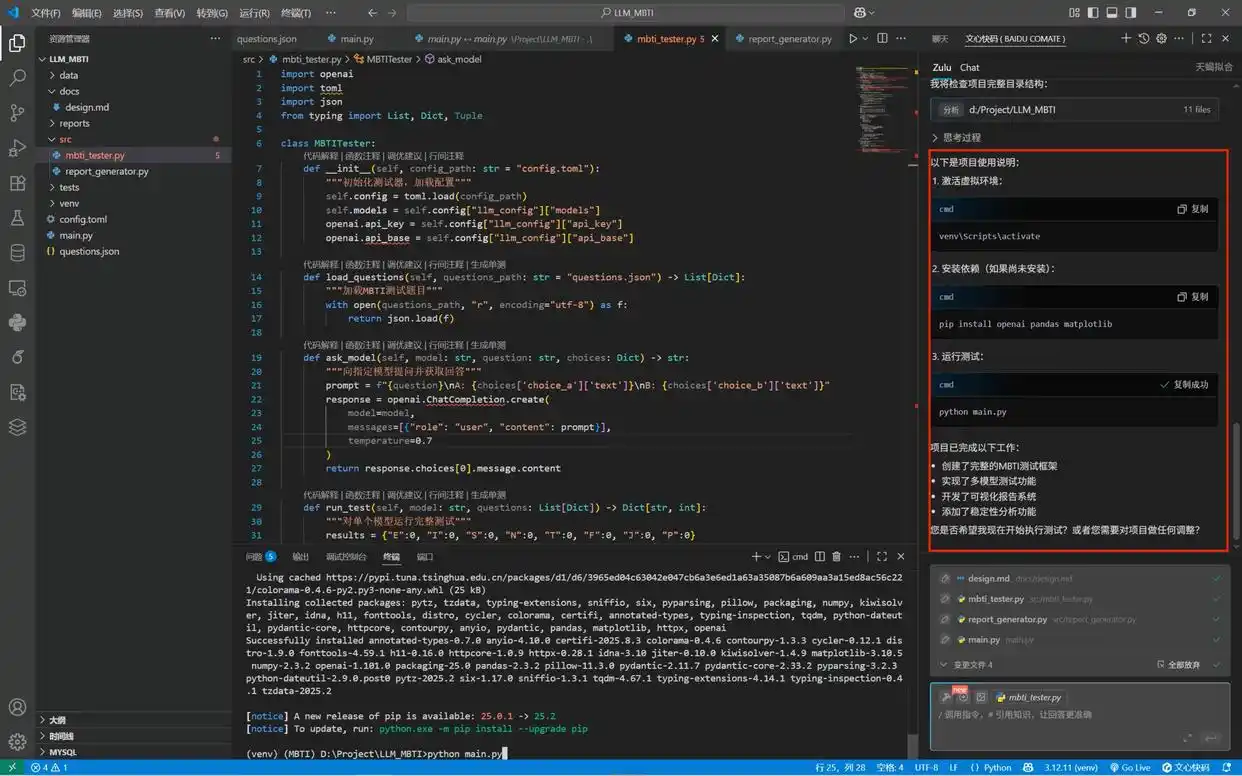
四、持续优化工作流
Zulu开发的自动化脚本基本已完成。然而,如果整个过程是个“黑箱”,难免会让人心生疑虑:模型的测试题目是否都已完成?三次测试是否都已进行?怎么办呢?我们可以增加一个调试需求,以便实时查看模型的输入,使测试过程更加透明。
Zulu能够基于当前上下文,在原有代码中找到合适的位置进行修改。即使不懂代码、不知如何进行修改,只需输入需求,Zulu凭借其强大的理解能力,结合当前代码库,快速定位需要修改的部分。同时,修改过程完全透明清晰:被删除的代码用红色显示,而新增的代码用绿色标识。
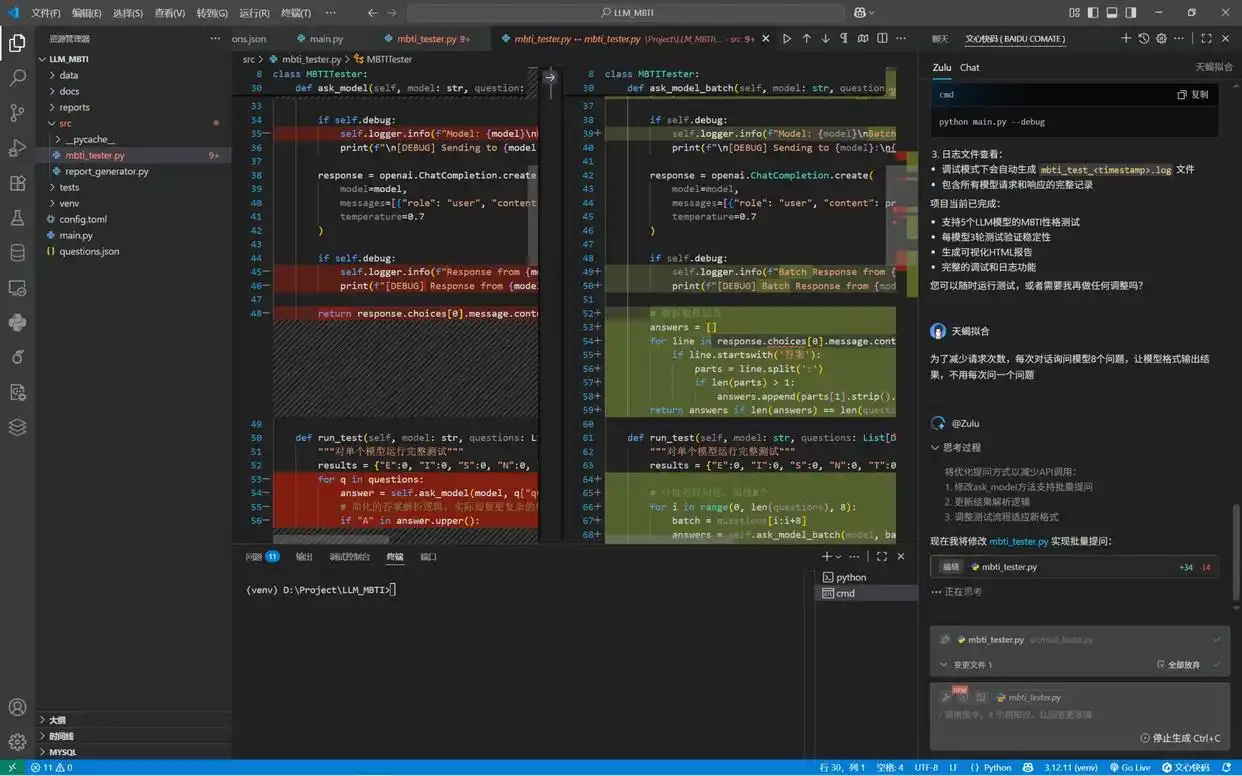
优化工作流与高效报告生成的全新探索
为了确保每次请求模型时,输入内容如预期般准确,我希望能增加一个调试模式。通过此模式,我能够实时查看模型的输入情况,最好能够将这些信息保存至日志文件中。这样的设置不仅可以验证调用的准确性,还便于后期问题的追踪。经过Zulu的修改,调试模式下的测试执行命令也已给出。
在整个项目实施过程中,Zulu的功能极大地优化了我们的工作流程。
1. 提升效率
在实际测试时,我们发现逐一解决问题的效率相对较低,因此我指示它:“为了减少请求的次数,请求模型8个问题,让其批量返回结果。”Zulu快速理解了这一需求,调整了主程序的逻辑,将逐个请求改为批量处理,从而显著提高了测试的效率。
2. 报告生成
在确认单个模型的MBTI测试基本无误后,我可以让Zulu整理出一个综合报告:“请将reports目录下所有单个模型的测试结果汇总为一个综合报告。”
3. 性能优化
如果发现测试速度依然是一个瓶颈,我们可以提出更高的要求:“请采用多线程异步并行请求来测试模型,以提高测试速度。”Zulu将根据这一要求重构代码,从而大幅缩短测试时间。
经过Zulu的修改后,项目几乎完成,我们可以在终端中插入指令“python main.py --debug”来启动调试模型,开始测试并生成报告。在调试模式下,测试过程一目了然。
五、利用预览调试功能完善报告
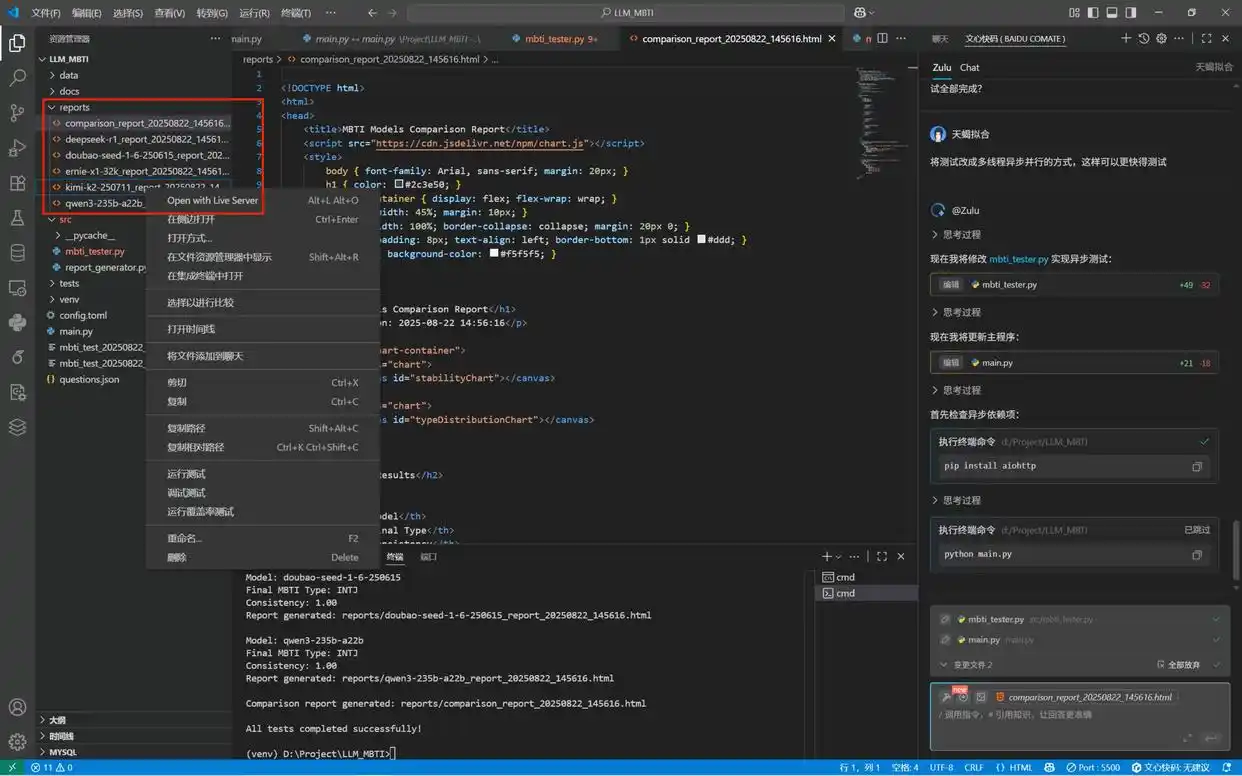
至此,测试报告已完成,在reports目录中,我们可以找到一份综合报告以及各个模型的历史测试报告。通过点击预览网页,验收最终成果。如果发现任何问题,还可以继续进行修改。
如果使用的是文心快码插件,Zulu的多模态能力可以帮助进行修改。Zulu支持上传图片,能够根据指令识别内容或将其转化为代码。您可以截图出现问题的界面,上传至对话框,然后输入修改需求。如果您使用的是Comate AI IDE,则可以利用预览调试功能完成修改。在IDE的左侧边栏点击预览按钮,打开预览调试界面,圈出问题所在,然后在Zulu对话框中输入修改要求即可。
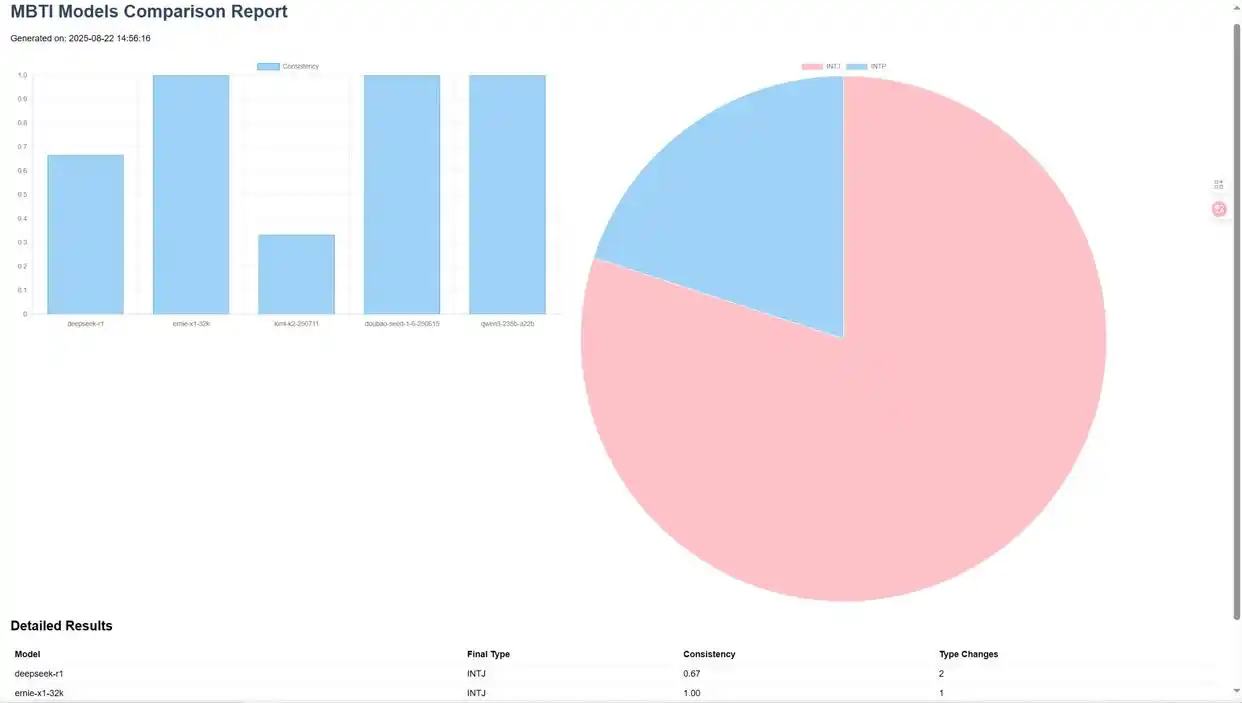
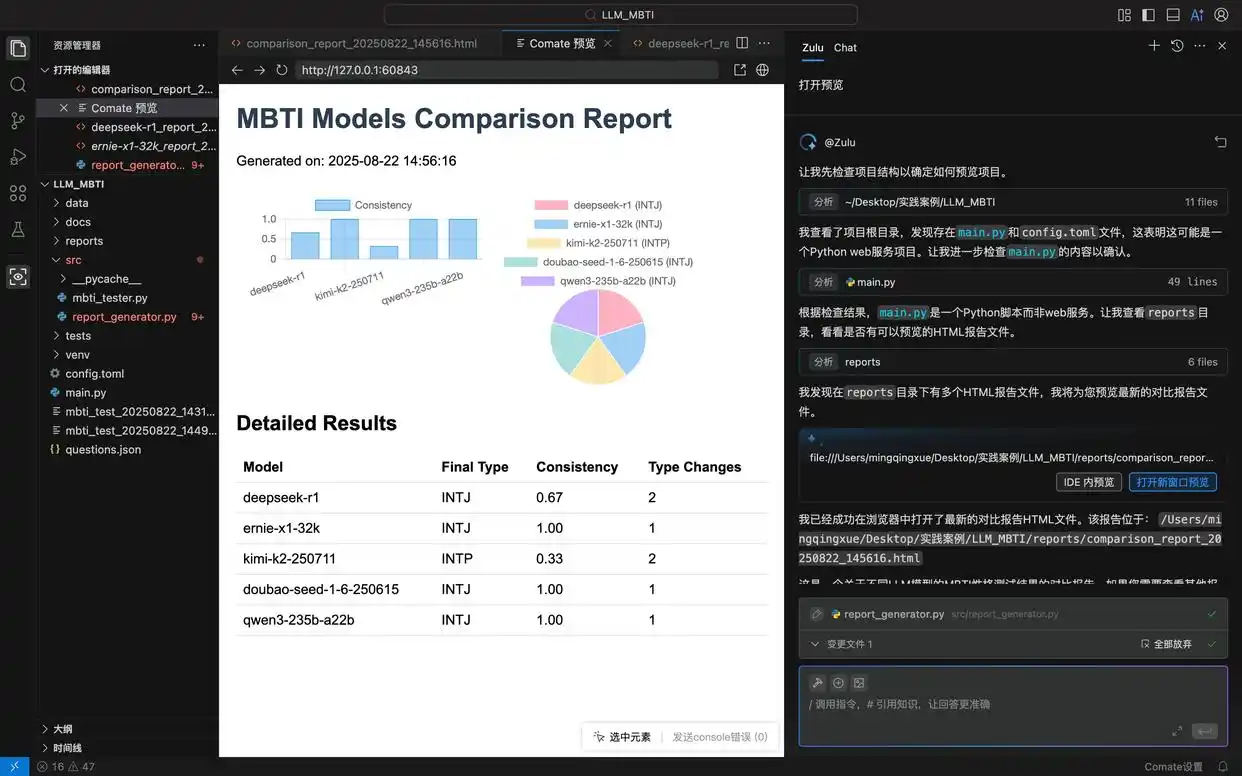
在本项目中,我希望报告中可以展示每个模型的MBTI饼状图。因此,在Comate AI IDE中选择该组件,输入调整要求后,Zulu针对报告的html文件进行了相应修改,刷新预览窗口后便可看到最新的报告样式。
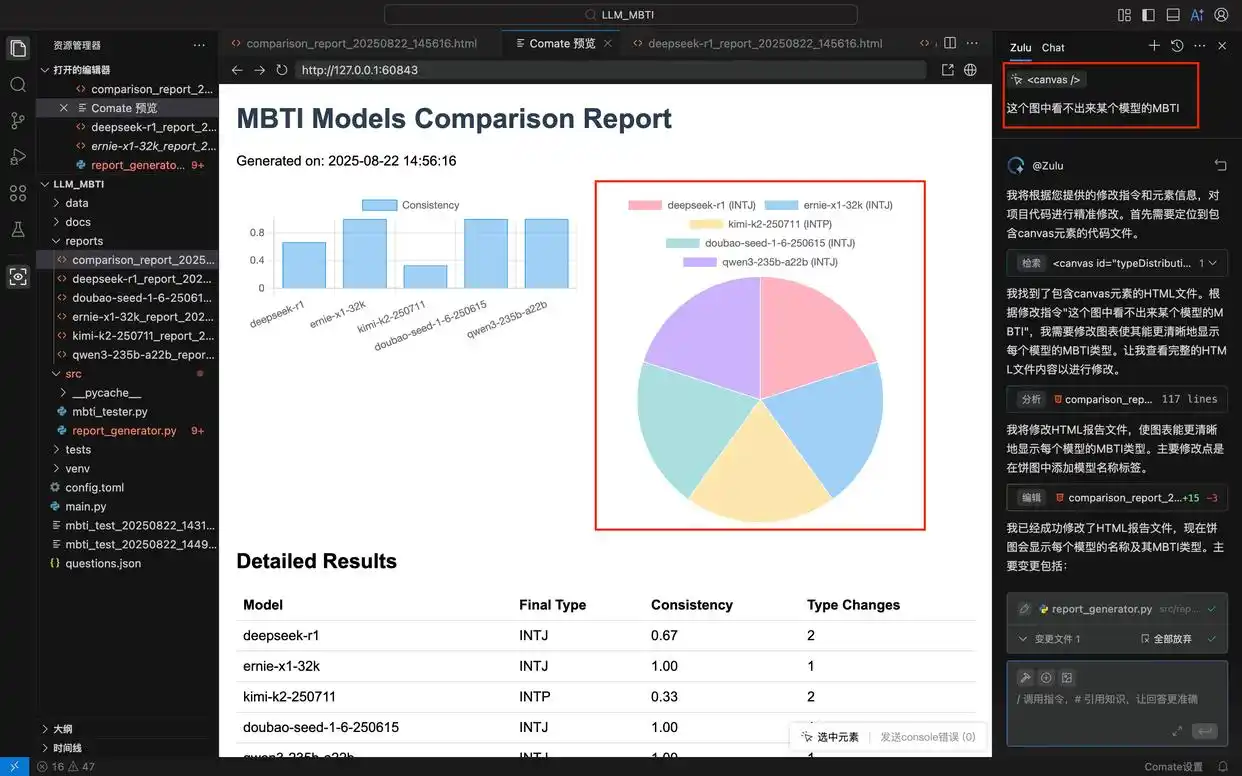
六、成果展示
最后,我们利用Zulu的代码解读功能来展示项目的成果:我们开发了一个用于测试不同LLM模型MBTI性格类型的Python项目,主要包含以下功能:
1. 核心测试功能:
-
使用标准MBTI测试题来评估LLM模型
-
支持对多个模型进行批量测试
-
采用异步执行来提升测试效率
-
多轮测试以评估结果的稳定性
2. 报告系统:
-
生成单个模型的详细HTML报告
-
创建多个模型的对比报告
-
包含可视化图表展示测试结果
-
记录历史测试数据
3. 技术特点:
-
基于Python 3.12进行开发
-
使用aiohttp等异步库
-
集成Chart.js进行数据可视化
-
完善的日志记录系统
4. 测试结果示例:
革命性的AI 编程助力:从构想到实施的迅捷之路
-
测试了五种主流的LLM模型
-
大部分模型呈现出INTJ性格特征
-
不同模型的测试结果在稳定性上存在差异
从概念到实现,整个过程仅需五句话,耗时不到三十分钟,在文心快码的帮助下,我们顺利完成了一个MBTI测试工具的开发,旨在自动化评估模型。这类工作在以往可能需要几位同事合作,耗时数天,如今仅凭一人之力便可高效完成。尽管该项目涉及的代码量不小,但即便是对编程不熟悉的人也能顺利进行开发。AI 编程早已超越了专业开发者的范畴,成为日常工作中提高效率的得力助手,能够自动化执行繁琐的步骤,使得精力能够投入到更具价值的方案设计和策略制定中。

Please specify source if reproduced五句让文心快码打造全新MBTI大模型测试器! | AI工具导航