
编程范式的框架
编程范式,或称为编程风格,指的是软件工程中的几种典型编程方式。常见的编程范式包括:函数式编程、命令式编程、声明式编程以及面向对象编程等。这些编程风格影响了开发者对程序运行方式的理解。在使用人工智能框架进行编码时,开发者通常会采用两种主要的编程范式:声明式编程和命令式编程。

本节将详细探讨这两种编程范式对人工智能框架的架构设计所产生的影响,同时分析当前主流的人工智能框架在这两种编程范式中的不同之处。
程序开发中的编程范式
-
命令式编程(Imperative):通过详细的指令告诉计算机如何处理任务,以实现预期的结果。
-
声明式编程(Declarative):仅指明所需的结果,计算机则自行决定执行过程。
编程与编程范式的关系
编程是开发者为解决特定问题而编写代码的过程,旨在通过计算机执行特定的运算逻辑,确保计算系统按照既定方式运行并最终得到预期结果。
为了使计算机能够理解人类的意图,必须将待解决问题的思路和方法以计算机能理解的形式表达出来,这样计算机才能根据指令逐步执行,完成特定任务。这种人与计算机之间的沟通过程便称为编程。
命令式编程
命令式编程(Imperative programming)是一种阐述计算机所需行为的编程方式,几乎所有计算机硬件的操作都基于这一范式。
其过程可以分为几个步骤:首先,需要将解决方案抽象为一系列概念性的步骤。接着,通过编程方式将这些步骤转化为程序指令集(算法),并按照特定顺序排列,以说明如何执行任务或解决问题。这表明,开发者必须清楚程序的目标,并告知计算机如何完成计算工作,包括每一个细节。简单来说,就是将计算机视为一个全程听从指令的设备。
因此,在命令式编程中,明确问题并将其抽象为算法是解决问题的关键步骤,之后再撰写具体的算法并实现问题的有效解决。
目前,开发者所接触的命令式编程主要集中在硬件控制和指令执行上。以人工智能框架 PyTorch 为例,它主要采用命令式编程的方式进行开发。
以下代码展示了一个简单的声明式编程过程:创建一个用于存储结果的集合变量 results,然后遍历数字集合 collection,判断每个数字是否大于 5,并将符合条件的数字添加到结果集合中。在这个过程中,我们需要向计算机指示每一步该如何执行。
results = []def fun(collection): for num in collection: if num > 5: results.append(num)
声明式编程
探秘声明式编程及其在AI框架中的运用
声明式编程(Declarative programming)是一种与命令式编程截然不同的编程模式。其核心理念在于描述期望的结果特性,让计算机理解目标,而不是具体的执行步骤。通过这种方式,声明式编程能够有效避免因执行过程而产生的副作用,而命令式编程则需要通过明确的算法逐步指示计算机完成任务。
副作用:在计算机科学中,函数的副作用(Side Effects)指的是在调用函数时,除了返回值外,还会对调用环境产生额外影响。这包括修改全局变量(函数外的变量)、改变输入参数,或者向控制台、管道输出数据等。
在声明式编程中,变量之间的关系通过函数、推理规则或项重写(term-rewriting)规则进行描述。其编译器或解释器采用固定的算法,从这些关系中得到结果。
目前,开发者所使用的声明式编程语言包括数据库查询语言(如SQL、XQuery)、正则表达式、逻辑编程和函数式编程等。在人工智能框架领域,以 TensorFlow1.X 为例,声明式编程的理念得到了充分体现。
以广泛使用的数据库查询语言 SQL 为例,它显著地体现了声明式编程的特征。用户无需创建变量来存储数据,而是直接向计算机说明需要查询的内容即可:
>>> SELECT * FROM collection WHERE num > 5
函数式编程的特点
函数式编程(Functional Programming)本质上也是一种编程范式,它在软件开发中尽量避免共享状态、可变状态和副作用。它将计算视为函数的计算,并且不依赖于程序状态或变化对象。理论上,函数式编程可以被视为一种声明式编程,因为它不需要处理可变状态,也不要求指定执行顺序。
其核心是只利用纯粹的数学函数进行编程,函数的输出仅依赖于输入参数,不会产生副作用,例如输入输出或状态变化。程序通过函数组合的方式进行构建,数据驱动着整个应用,状态在不同的纯函数之间流动。与命令式编程的面向对象方法相比,函数式编程更倾向于声明式,代码更加简洁明了,预测性更强,且可测试性更高,因此可以归类为一种特殊的声明式编程范型。
函数式编程的一个重要特征是“函数第一位”(First Class),这意味着函数可以出现在任何地方,例如可以将一个函数作为参数传递给另一个函数,甚至可以将函数作为返回值。以下是 Python 代码的示例:
def fun_add(a, b, c): return a + b + cdef fun_outer(fun_add, *args, **kwargs): print(fun_add(*args, **kwargs))def fun_innter(*args): return argsif __name__ == '__main__': fun_outer(fun_innter, 1, 2, 3)
AI框架中的编程范式
无论是 PyTorch 还是 Tensorflow,主流的 AI 框架均以 Python 为主的高级语言作为前端,提供了脚本式的编程体验。后端则采用更底层的编程模型和语言进行开发。后端的高性能可复用模块与前端紧密结合,前端通过驱动后端的方式执行。这些 AI 框架为用户提供了声明式(declarative programming)和命令式(imperative programming)两种编程范式。
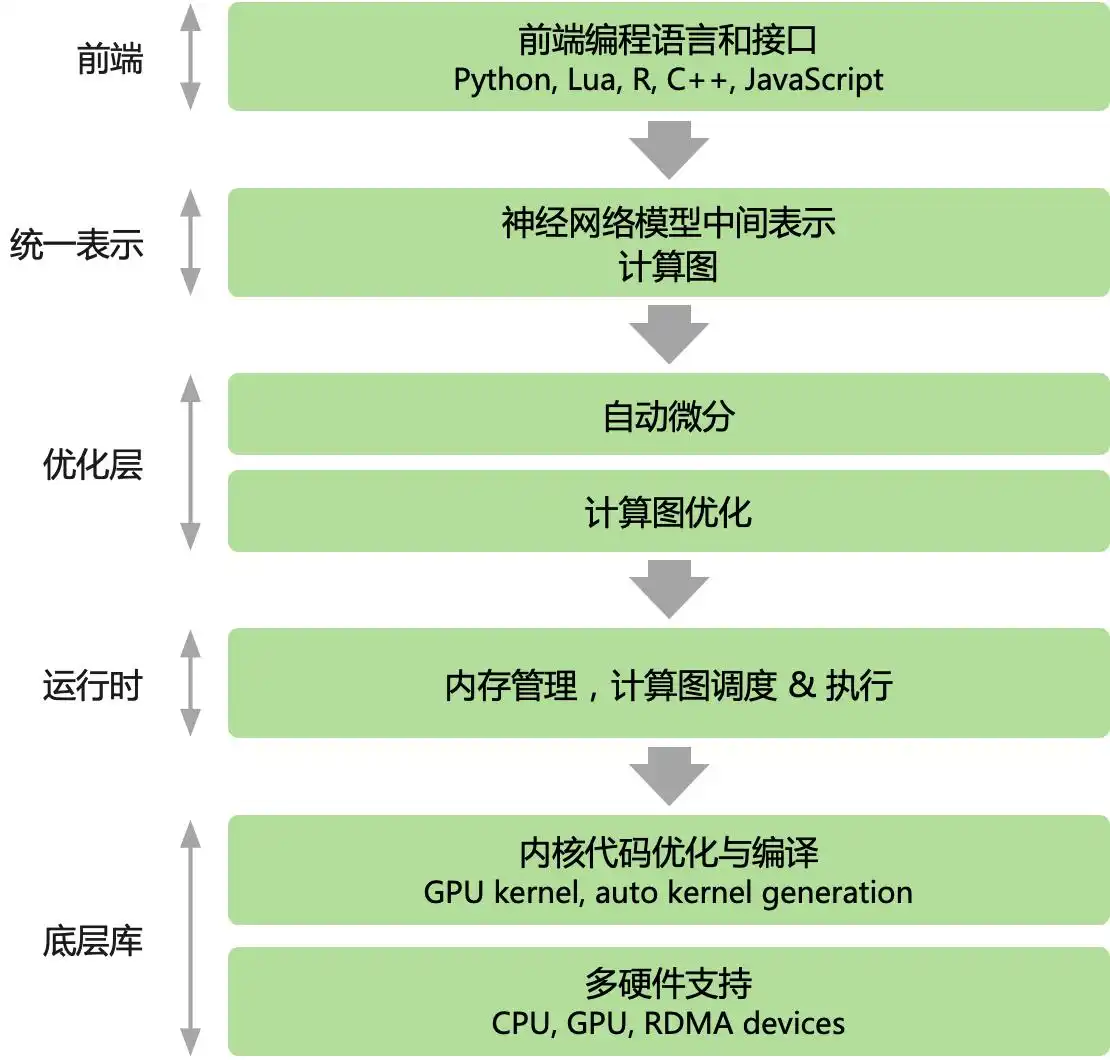
探索主流AI框架的编程模式
在当前流行的人工智能框架中,TensorFlow 提供了一种声明式的编程体验,而 PyTorch 则侧重于命令式编程。这两种模型并非截然分开,多阶段编程和即时编译技术的引入,使得两种编程方式可以灵活结合。随着如 TensorFlow Eager 模式和 PyTorch JIT 的出现,主流 AI 框架逐步采用混合编程,旨在兼顾两者的优势。
命令式编程
在命令式编程模式中,前端的 Python 语言直接控制后端算子的执行,用户的表达式会被立即求值,这种方式被称为define-by-run。开发者需要逐层编写神经网络模型,同时定义每个训练迭代中所需的计算任务。程序在执行时,系统会根据 Python 语言的动态解析特性,逐行解析并执行具体的计算,因此形成了动态计算图(动态图)。
命令式编程的优势在于其调试的便利性和高灵活性。然而,由于在执行之前缺乏对整个算法的统一描述,这也使得它错失了编译时优化的机会。
与之相比,命令式编程对数据和控制流的静态限制较小,这样使其调试更加方便,灵活性更佳。然而,缺乏在程序执行前对计算图的全面描述也限制了编译时各种优化手段的应用。
在 PyTorch 中,其编程特色体现在即时执行上,这种风格更加符合声明式编程。接下来,我们将用 PyTorch 构建并训练一个简单的两层神经网络模型:
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitimport torchimport torch.nn as nnimport torch.optim as optim# 导入数据data = pd.read_csv('mnist.csv')X = data.iloc[:, 1:].valuesy = data.iloc[:, 0].values# 分割数据集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# 将数据转换为张量X_train = torch.tensor(X_train, dtype=torch.float)X_test = torch.tensor(X_test, dtype=torch.float)y_train = torch.tensor(y_train, dtype=torch.long)y_test = torch.tensor(y_test, dtype=torch.long)# 定义模型class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.fc1 = nn.Linear(784, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.fc1(x) x = self.fc2(x) return xmodel = Net()# 定义损失函数和优化器criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters())# 训练模型for epoch in range(5): # 将模型设为训练模式 model.train() # 计算模型输出 logits = model(X_train) loss = criterion(logits, y_train)
声明式编程
在声明式编程模型中,前端语言的表达式并不直接执行,而是构建一个完整的前向计算过程表示,经过优化的数据流图再进行执行,这种方式称为define-and-run。开发者首先定义整个神经网络模型的前向表示代码,由于整体模型的定义明确,AI 框架的后端会将其编译成静态计算图(简称:静态图)以供执行。
其执行流程相对直接:前端开发者书写的 Python 表达式不会立即执行,而是会通过 AI 框架提供的 API 定义接口,构建一个完整的前向计算过程表示。最终,经过对计算图的优化后再进行执行。
采用声明式编程的 AI 框架带来的优势包括:
-
在执行前能够获得整个程序(即整个神经网络模型)的完整视图
-
在实际运行深度学习之前,可以执行编译优化算法
-
实现极致的性能提升
然而,这种编程方式也存在一些明显的缺陷:
AI框架中的编程风格与深度学习的未来
-
神经网络在AI框架中受到API有限定义的影响,导致数据类型和控制流受到制约。
-
神经网络的特殊性质要求AI框架预先设定相应的概念(DSL),这使得调试变得不方便,并且灵活性受到限制。
以Google的TensorFlow 1.X为例,其编程风格特点包括计算图(Computational Graphs)、会话(Session)及张量(Tensor),这些特点体现了典型的声明式编程方式。接下来,我们将通过TensorFlow实现一个具有隐含层的全连接神经网络,其优化目标是最小化预测值与真实值之间的欧氏距离。该实现通过基本的TensorFlow操作构建一个计算图,然后反复执行该图以训练网络。
import tensorflow as tfimport numpy as np# 首先构建计算图# N是batch大小;D_in是输入大小。# H是隐单元个数;D_out是输出大小。N, D_in, H, D_out = 64, 1000, 100, 10# 输入和输出是placeholder,在用session执行graph的时候# 我们会feed进去一个batch的训练数据。x = tf.placeholder(tf.float32, shape=(None, D_in))y = tf.placeholder(tf.float32, shape=(None, D_out))# 创建变量,并且随机初始化。 # 在Tensorflow里,变量的生命周期是整个session,因此适合用它来保存模型的参数。w1 = tf.Variable(tf.random_normal((D_in, H)))w2 = tf.Variable(tf.random_normal((H, D_out)))
在Forward阶段,模型的预测值y_pred被计算出来。值得注意的是,与PyTorch的实现有所不同,此处并不会立即执行计算,而只是对计算过程进行了定义,真正的计算将在session.run时才得以实现。
h = tf.matmul(x, w1)h_relu = tf.maximum(h, tf.zeros(1))y_pred = tf.matmul(h_relu, w2)# 计算loss loss = tf.reduce_sum((y - y_pred) ** 2.0)# 计算梯度grad_w1, grad_w2 = tf.gradients(loss, [w1, w2])
通过梯度下降法更新参数。需要强调的是,assign指令仅仅是定义了一个更新操作,而并未真正执行。在TensorFlow中,更新操作是计算图的组成部分,而在PyTorch中,由于其动态“实时”的计算特性,参数的更新则被视为普通的Tensor计算,不再属于计算图的一部分。
learning_rate = 1e-6new_w1 = w1.assign(w1 - learning_rate * grad_w1)new_w2 = w2.assign(w2 - learning_rate * grad_w2)# 计算图构建好了之后,我们需要创建一个session来执行计算图。with tf.Session() as sess: # 首先需要用session初始化变量 sess.run(tf.global_variables_initializer()) # 创建随机训练数据 x_value = np.random.randn(N, D_in) y_value = np.random.randn(N, D_out) for _ in range(500): # 用session多次的执行计算图。每次feed进去不同的数据。 # 这里是模拟的,实际应该每次feed一个batch的数据。 # run的第一个参数是需要执行的计算图的节点,它依赖的节点也会自动执行, # 因此我们不需要手动执行forward的计算。 # run返回这些节点执行后的值,并且返回的是numpy array loss_value, _, _ = sess.run([loss, new_w1, new_w2], feed_dict={x: x_value, y: y_value}) print(loss_value)
函数式编程的优势
无论是JAX还是MindSpore,都采用了函数式编程范式,这在高性能计算、科学计算与分布式处理方面展现出显著的优势。
JAX框架专注于GPU/TPU的高效并行计算,其与其他AI框架的不同之处在于,它将神经网络计算与数值计算相结合,且在接口上兼容NumPy、Scipy等Python原生数据科学库。此外,JAX还扩展了分布式、向量化、高阶求导及硬件加速功能,其编程风格体现了函数式编程的特征,包括无副作用和Lambda闭包等。而华为推出的MindSpore框架则通过其函数式可微分编程架构,使用户能够专注于机器学习模型的数学原生表达。
本节总结

Please specify source if reproduced选择AI框架时应考虑的编程方式有哪些? | AI工具导航