
编辑:杜伟
卡内基梅隆大学(CMU)对多种现有的开源与闭源人工智能代码生成模型进行了详尽的系统性研究,特别关注它们在 C、C++、Python 等 12 种编程语言上的代码自动补全能力。
近来,语言模型在编程语言源代码的建模方面展现出了卓越的表现。这些模型不仅具备自动生成代码的能力,还能根据自然语言描述生成相应的代码,展现出在多项下游任务中的良好适应性。目前,基于人工智能的编程辅助领域,状态最先进(SOTA)的语言代码模型(如 Austin 等人 (2021))已经取得了显著进展。此外,OpenAI推出的模型已在实际生产工具 GitHub Copilot 中应用,作为一个基于用户上下文生成代码的开发者助手。
尽管大型语言代码模型获得了巨大的成功,但这些最强的模型通常并不对外开放,这一情况限制了其在资源有限的公司中的使用,同时也制约了资源匮乏的机构在该领域的研究。例如,Codex通过黑盒 API 提供收费访问,但其模型权重和训练数据并未公开,这使得研究者无法对模型进行微调或适应于其他任务。更重要的是,无法访问模型内部结构也使得研究社区无法深入探讨其他关键问题,如可解释性、模型蒸馏以实现更高效的部署,以及融合检索等附加组件。
与此同时,像 GPTNeo、GPT-J 和 GPT-NeoX 等中型和大型的预训练语言模型则是开放可用的。尽管这些模型是在包括新闻文章、在线论坛以及少量 GitHub 软件存储库等多样化文本资源上进行训练的,但它们仍能生成具有合理性能的源代码。此外,还有一些全新的开源语言模型,如 CodeParrot,其训练数据专注于 180GB 的 Python 代码。
然而,这些模型在规模和训练方法上存在多样性,并且彼此之间缺乏有效的比较,导致许多建模和训练设计决策的影响尚不明确。
近日,CMU计算机科学学院的研究者们对现有的代码生成模型进行了系统评估,涵盖了 Codex、GPT-J、GPT-Neo、GPT-NeoX 和 CodeParrot。他们希望通过对比这些模型,深入理解代码建模设计决策的未来发展,指出一个关键的空缺:迄今为止,尚未出现专门针对多种编程语言的大规模开源语言模型。为此,研究者们推出了三个参数量从 160M 到 2.7B 的新模型,并命名为“PolyCoder”。

论文地址:[https://arxiv.org/pdf/2202.13169.pdf](https://arxiv.org/pdf/2202.13169.pdf)
项目地址:[https://github.com/VHellendoorn/Code-LMs](https://github.com/VHellendoorn/Code-LMs)
研究者首先对 PolyCoder、开源模型和 Codex 的训练设置进行了比较;其次,在 HumanEval 基准上评估这些模型,比较不同参数大小和训练步数的模型如何扩展,以及不同温度如何影响生成质量;最后,针对 12 种语言,研究者创建了相应的未见过的评估数据集,以评估各个模型的困惑度。
结果显示,尽管 Codex 宣称在 Python 语言中表现最佳,但在其他编程语言的表现上同样出色,甚至超越了在 Pile(为训练语言模型设计的 825G 数据集)上训练的 GPT-J 和 GPT-NeoX。然而,在 C 语言中,PolyCoder 模型的困惑度却低于所有其他模型,包括 Codex。
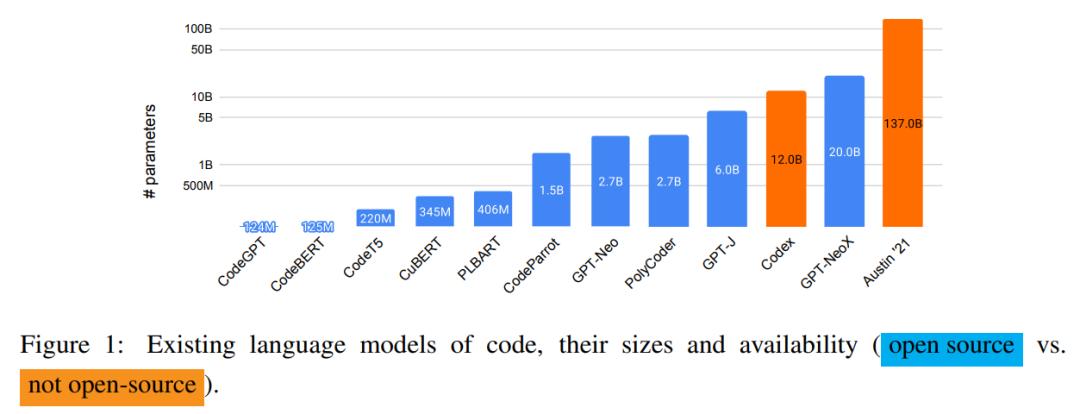
下图 1 展示了现有语言代码模型的规模和可用性,除了 Codex 和 Austin'21,其他均为开源模型。
研究者还讨论了在代码语言建模中使用的三种流行的预训练方法,具体如下图 2 所示。

评估设置
研究者使用外部和内部基准对所有模型进行了评估。
外部评估。代码建模的一个重要下游任务是根据自然语言描述生成代码。遵循 Chen 等人 (2021) 的方法,所有模型在 HumanEval 数据集上进行了评估。该数据集包含 164 个通过代码注释和函数定义形式描述的提示,涵盖了参数名称和函数名称,并附带测试用例以验证生成的代码是否正确。
内部评估。为了评估不同模型的内部性能,研究者在一组未见过的 GitHub 存储库上计算了每种语言的困惑度。为防止在训练到测试过程中出现数据泄露,研究者在评估数据集中移除了在 Pile 训练数据集中出现的 GitHub 部分。
模型比较
研究者主要选择了自回归预训练语言模型,这种模型最适合于代码补全任务。具体来说,他们评估了 Codex,这是一款由 OpenAI 开发的模型,目前已在实际应用中展现出优秀的性能。Codex 在一个179GB(去重后)的数据集上进行训练,该数据集包含了自 2020 年 5 月从 GitHub 收集的 5400万公开 Python 存储库。
至于开源模型,研究者比较了 GPT 系列中的三种变体——GPT-Neo(27亿参数)、GPT-J(60亿参数)和 GPT-NeoX(200亿参数)。其中,GPT-NeoX 是目前最大规模的开源预训练语言模型。这些模型都在 Pile 数据集上进行训练。
目前,社区尚未有专门针对多编程语言代码进行训练的大规模开源语言模型。为了填补这一空白,研究者在 GitHub 中涵盖 12 种不同编程语言的存储库集合上训练了一个 27亿参数的模型——PolyCoder。
PolyCoder 的数据
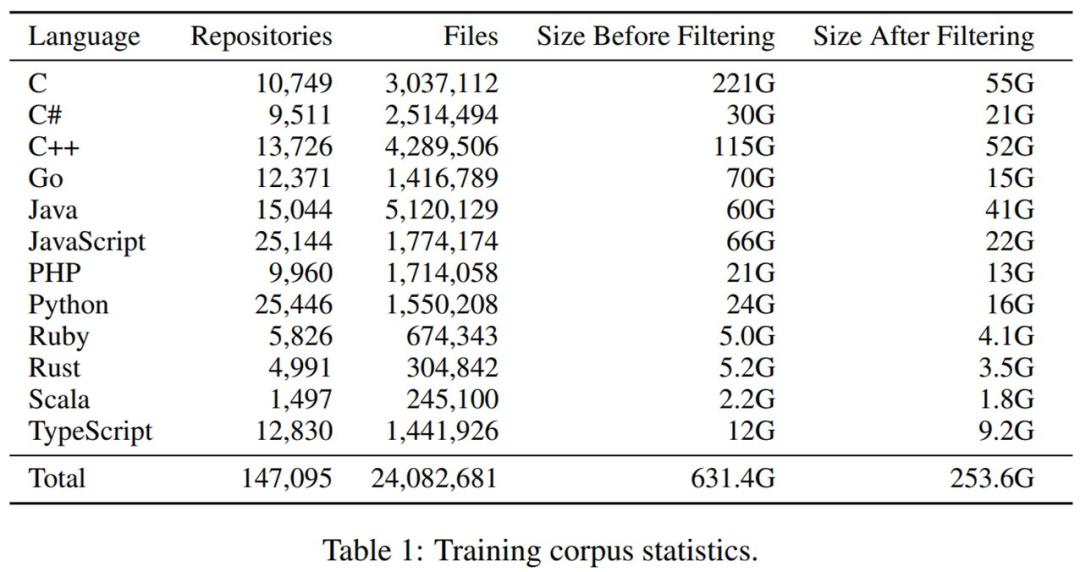
原始代码库集合。研究者针对 12 种流行编程语言克隆了 2021 年 10 月在 GitHub 上 Star 数超过 50 的最流行存储库。最初未过滤的数据集总计为 631GB,共包含 3890万个文件。
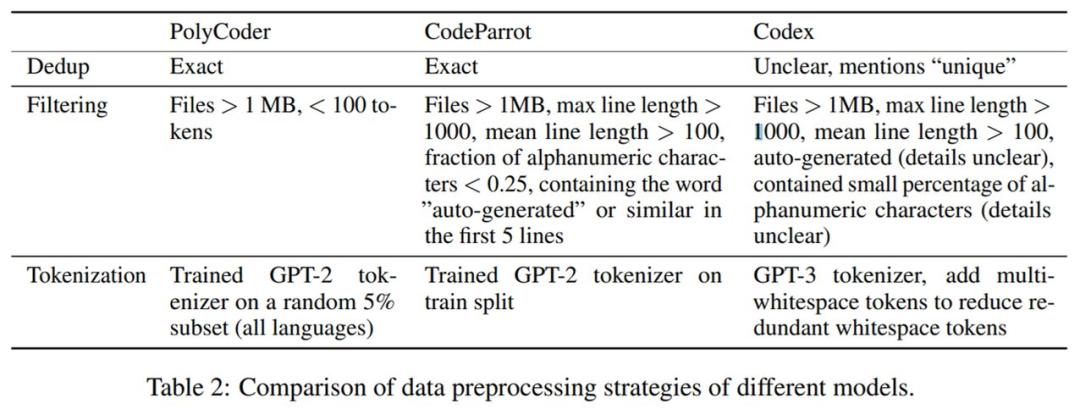
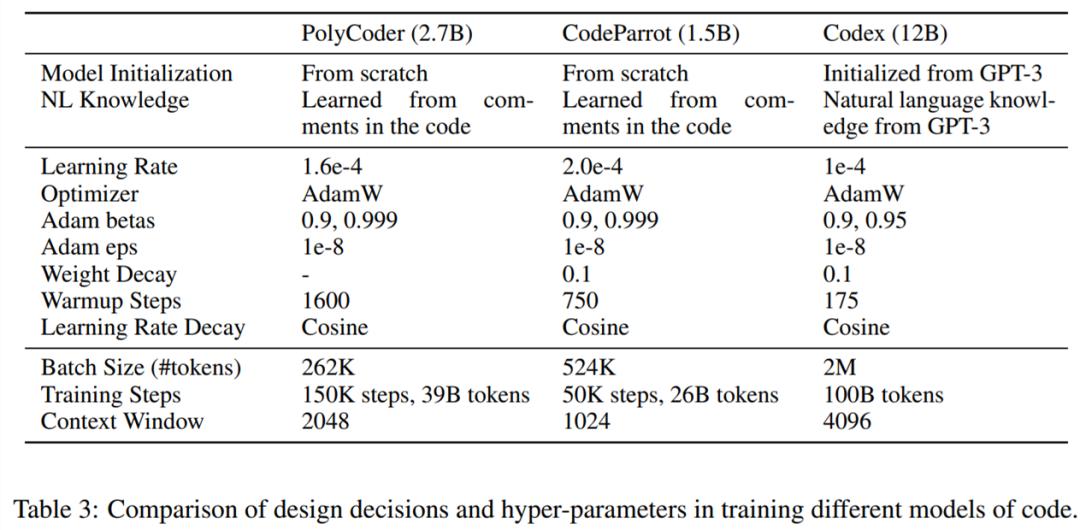
接下来进行数据预处理。PolyCoder 的数据预处理策略与 CodeParrot 和 Codex 的策略进行了详细对比,如下表 2 所示。
最后进行了重复数据的删除和过滤。总体来看,去除过大和过小的文件并删除重复数据后,文件总量减少了38%,数据集大小减少了61%。下表 1 则展示了过滤前后数据集大小的变化。
PolyCoder 的训练
考虑到预算,研究者选用了 GPT-2 作为模型架构。为探讨模型规模变化的影响,他们分别训练了参数量为 1.6亿、4亿和 27亿的 PolyCoder 模型,并将27亿参数的模型与 GPT-Neo 进行了公平比较。
研究者利用 GPT-NeoX 工具包在一台配备8块英伟达 RTX 8000 GPU 的机器上高效并行地训练模型。训练 27亿参数的 PolyCoder 模型耗时约6周。在默认设置下,PolyCoder 模型应训练32万步,但因资源限制,他们将学习率衰减减至原来的一半,最终训练了15万步。
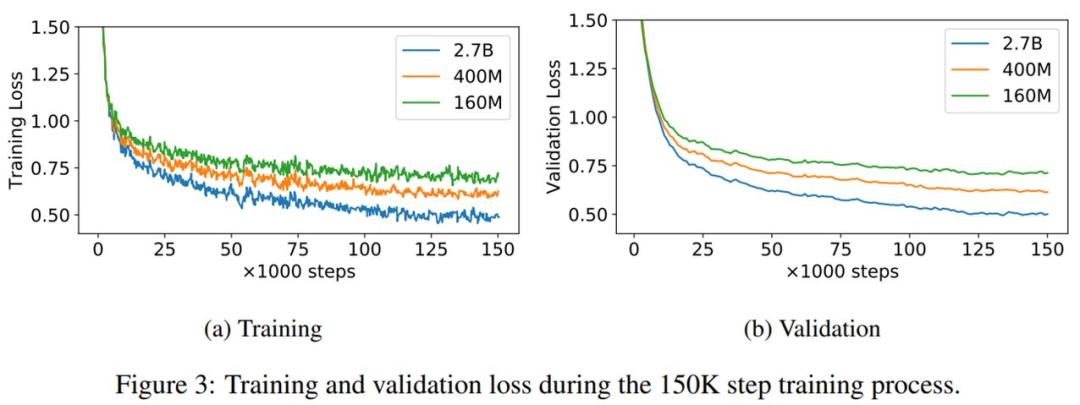
1.6亿、4亿和27亿参数的 PolyCoder 模型的训练和验证损失曲线如下图 3 所示。从图中可以看出,即使训练了15万步后,验证损失依然呈下降趋势。
### 不同代码模型设计决策与超参数比较分析
下表3呈现了在训练多种代码模型时的设计决策及超参数的对比情况。
实验结果
外部评估
整体表现如表4所示。在当前的模型中,PolyCoder 相较于同等规模的 GPT-Neo 和更小的 Codex 300M 显得较为逊色。总体而言,PolyCoder 的表现不及 Codex 和 GPT-Neo/J,但优于 CodeParrot。
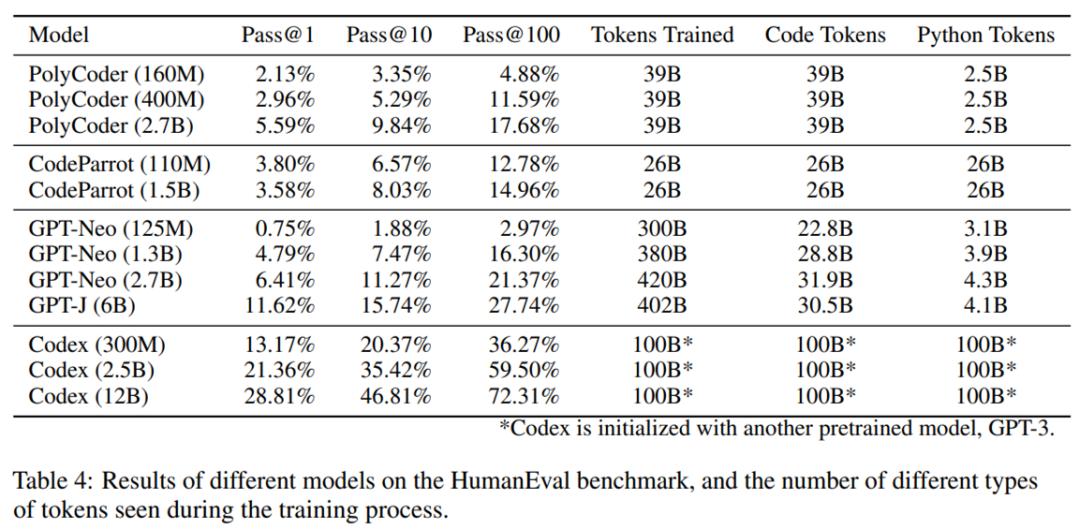
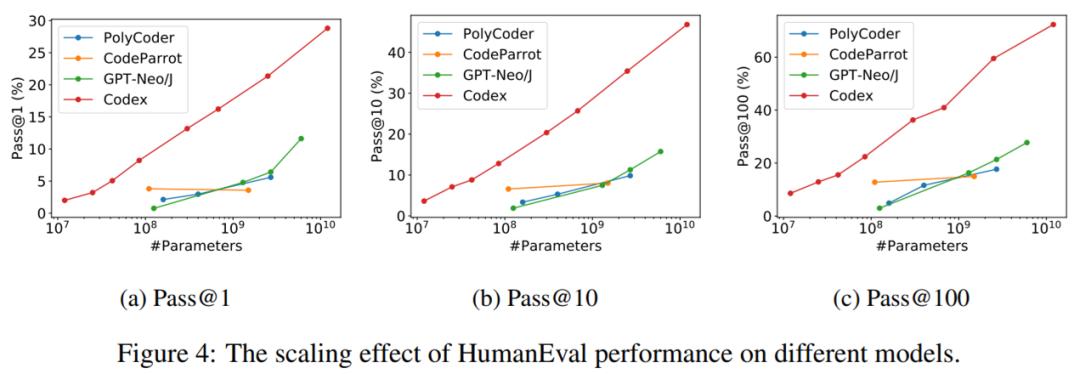
缩放效应。为深入探讨模型参数数量对 HumanEval 代码完成性能的影响,研究者在下图4中展示了 Pass@1、Pass@10 和 Pass@100 的性能变化趋势。
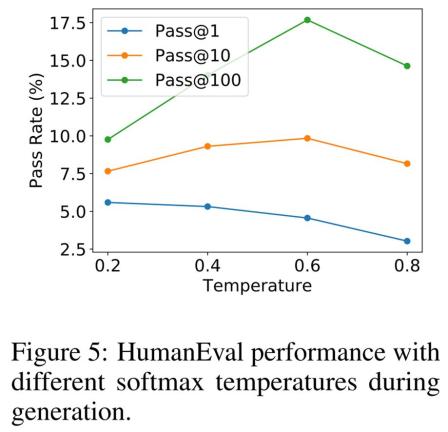
温度效应。所有上述结果均通过在不同温度下对语言模型进行采样,并选取每个指标的最佳值而得。研究者同样关注不同温度对最终生成质量的影响,其结果如图5所示。
内部评估
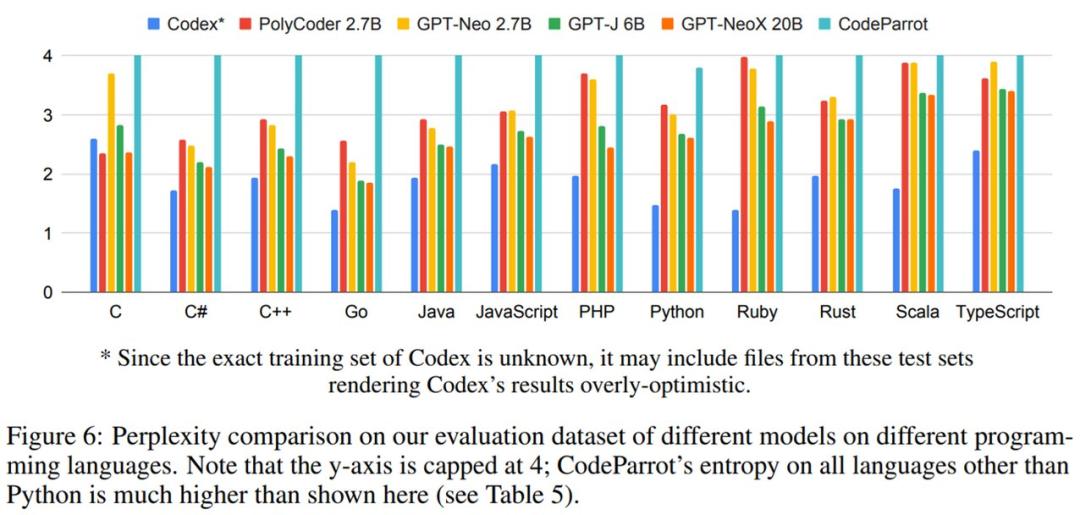
各模型在评估数据集中的困惑度结果如图6所示。困惑度的最高得分为4。可以看出,PolyCoder 在 C 语言上的表现优于 Codex 及其他所有模型。而在与开源模型的比较中,PolyCoder 在 C、JavaScript、Rust、Scala 和 TypeScript 语言上都超过了同规模的 GPT-Neo 2.7B。
此外,除了 C 语言之外的其他11种语言,包含 PolyCoder 在内的所有开源模型的表现均不及 Codex。
© 结尾
转载请联系本公众号以获取授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《CMU推出开源AI代码生成模型,C语言表现优于Codex》

Please specify source if reproducedCMU推出开源AI代码生成模型,C语言性能超越Codex | AI工具导航