
近期,AI编程工具Cursor的表现如日中天,展现出卓越的性能和令人瞩目的成果。最近,Cursor的一位关键研究者参与撰写的一篇论文被公开,文中提出了一种新的方法,旨在通过使用自然语言进行规划,来增强Claude 3.5 Sonnet等大型语言模型的代码生成能力。
具体而言,研究团队提出的这一方法被命名为PlanSearch(规划搜索)。该团队由Scale AI主导,论文的第一作者Evan Wang是Scale AI的研究者,第二作者Federico Cassano则已加入备受关注的AI编程工具公司Cursor。他在创立GammaTau AI项目中发挥了重要作用,该项目旨在推动AI编程的普及。此外,他还积极参与BigCode项目,该项目致力于开发用于AI编程的StarCoder系列大型语言模型。

-
论文标题:Planning In Natural Language Improves LLM Search For Code Generation
-
论文地址:https://arxiv.org/pdf/2409.03733
在论文的开头,研究团队引用了强化学习领域权威Sutton的经典文章《The Bitter Lesson(苦涩的教训)》,并提到该文中揭示的Scaling Law的两个核心原则:学习与搜索。随着大型语言模型的迅猛发展,人们对「学习」是否有效的质疑已逐渐消失。然而,传统机器学习领域中表现良好的「搜索」策略如何进一步提升大模型的能力,依然是一个待解的难题。
当前,模型在「搜索」应用上的主要障碍是其生成的答案往往缺乏多样性,表现相似。这一问题可能源于模型在预训练后,在特定数据集上进行的进一步训练,以适应特定任务或应用场景。
大量实证研究表明,许多大型语言模型通常被优化为产生单一的正确答案。例如,图中所示的DeepSeek-Coder-V2-Lite-Base在与其基础模型的对比中,起初表现并不突出,但随着生成答案的多样性减少,情况逆转。多种模型均呈现出这种趋势:经过特殊指令调整的模型在仅生成一个答案的情况下(pass@1)通常表现优于基础模型,但当要求生成多个答案时,这种优势可能会减弱,甚至在某些情况下完全反转。
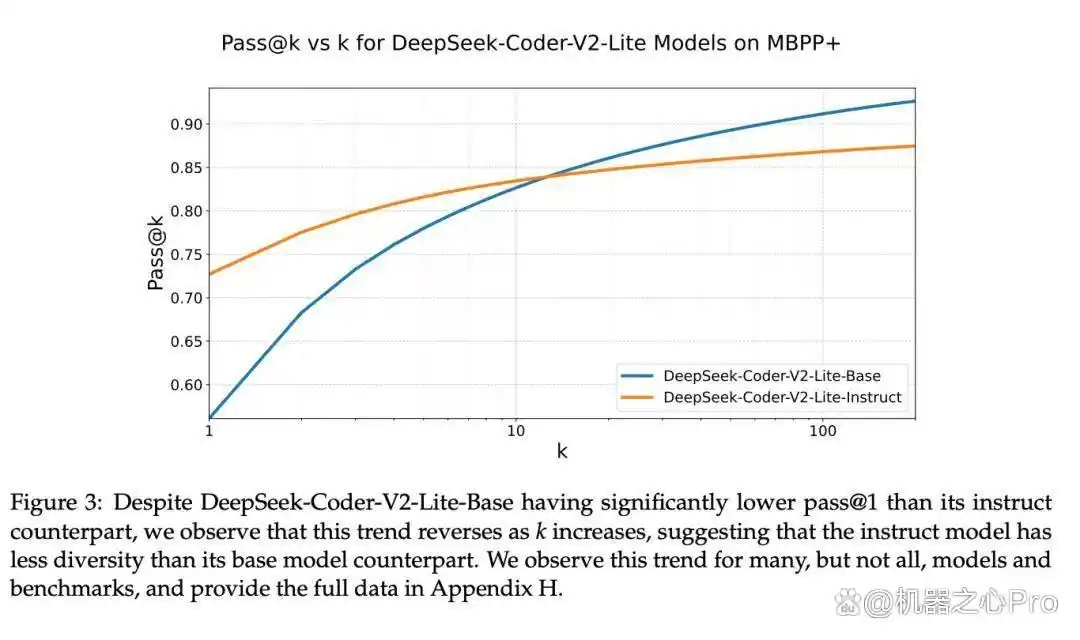
提升模型多样性与搜索能力的新方法
在生成答案时,模型的多样性不足,导致搜索效果受到严重影响。尤其是在极端情况下,如使用“贪心解码”策略时,模型所提供的答案往往高度相似,这些答案是从模型中重复提取的。在这种情况下,即便模型投入了更多的推理时间,也难以得到更理想的搜索结果。
对于当前市场上的大型模型排行榜,例如 LMSYS Chatbot Arena、LiveCodeBench 和 OpenLLMLeaderboard,其实并未能有效反映模型在回答多样性方面的缺陷。这些排行榜主要衡量模型在单一示例上的通过率,未考虑其在更广泛场景中的表现。虽然快速响应用户需求是模型的基本要求,但仅凭单一样本的回答质量来评估聊天机器人的性能,显然是不够全面的。
为了解决上述问题,研究者们对如何增强大语言模型在推理过程中的回答多样性展开了深入研究。他们提出一个假设,认为要使模型输出的答案更为丰富,必须在自然语言概念和想法的广阔空间中进行探索。
为了验证这一假设,研究团队进行了多项实验。首先,他们观察到,当模型获得一些简单的草图(这些草图是从能够解决问题的代码中“回译”而来的)时,模型能够依据这些草图生成正确的最终程序。其次,研究人员还发现,若让模型在尝试解决问题前,先在 LiveCodeBench 上进行一些思路构思(这一过程称为思路搜索),再看看模型能否利用这些想法来解决问题。
实验结果显示,模型可能完全无法解决问题(准确率为 0%),也可能完美地解决问题(准确率为 100%)。这表明,模型在尝试解决问题时,其成功与否主要依赖于最初的构思(草图)的准确性。
基于这些实验结果,研究人员认为提升 LLM 代码搜索能力的自然途径在于:先寻找正确的思路,再进行实现!
因此,规划搜索(PlanSearch)方法由此而生。
与以往的搜索方法(通常是只针对单个 token、代码行或整个程序)不同,规划搜索着眼于当前问题的解决方案规划。在这里,规划的定义是:为某个特定问题提供的高层次观察与草案的集合。
新方法的探索:规划搜索的应用
为了制定出新的解决方案,规划搜索会生成大量与特定问题相关的观察,并将这些观察整理成一系列候选方案,以便有效应对问题。
在这个过程中,需要对所有生成的观察的每一个可能子集进行评估,以此来最大化探索思维的广度,最终将成果转化为具体的代码解决方案。
研究团队的实验结果显示,规划搜索方法在推理和计算效率的表现上,明显优于传统的重复采样和直接的思路搜索方法。
方法概述
在此次研究中,团队考察了多种技术,包括重复采样、思路搜索以及新颖的规划搜索。前两种方法显而易见,而我们将特别聚焦于新提出的规划搜索。
研究团队注意到,尽管重复采样和思路搜索可以有效提升基准测试的性能,但在许多情况下,即使在高温条件下,多次提示(pass@k)所产生的代码变化也微乎其微。这些变化往往仅限于一些细节,无法解决思路中的根本问题。
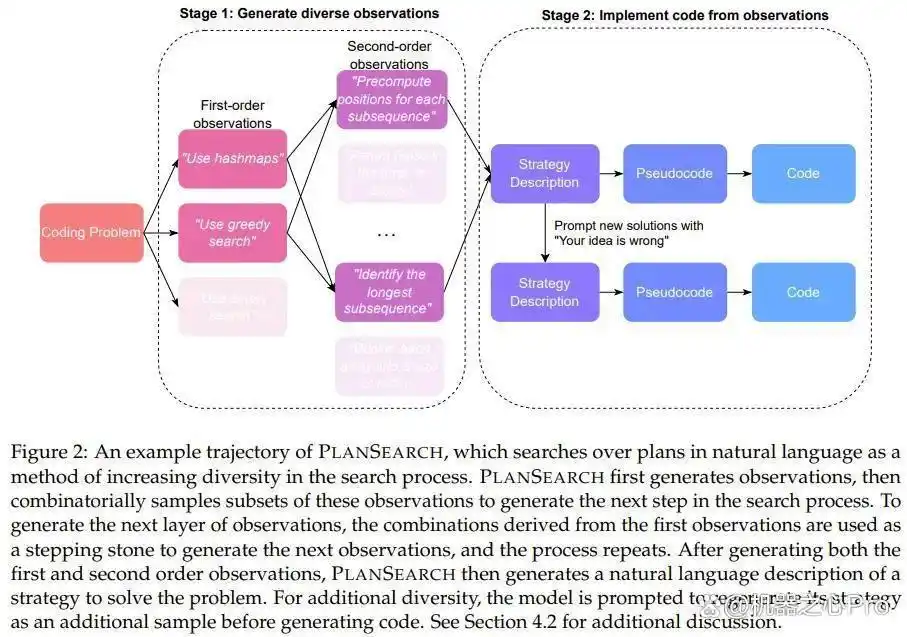
接下来,我们将详细介绍规划搜索的具体过程:
1. 通过提示获取观察
设想一个问题陈述 P,接着通过提示 LLM 来获取与该问题相关的「观察」或提示信息。我们将这些观察记录为 O^1_i,i 的范围为 {1, . . . , n_1},因为它们属于一阶观察。一般来说,n_1 的数量通常在 3 到 6 之间,具体数量则依赖于 LLM 的输出。为了利用这些观察以启迪未来的思路,团队构建了 O^1_i 的集合 S^1,并从中提取出最多包含两个元素的所有子集。每个子集被标记为 C^1_i,i 的范围为 {1, . . . , l_1}。
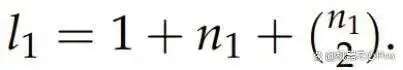
2. 推导新的观察
因此,所有的观察结果可以构建成一棵深度为 1 的有向树,树的根节点为 P,每个 C^1_i 则通过一条从 P 到 C^1_i 的边相连。
接下来,针对每个叶节点 C^1_i,重复上述过程,从而形成一个二阶观察集合 S^2。为了获得这些二阶观察,团队在提示模型时,将原始问题 P 及 C^1_i 中的所有观察一同包含在内,这些观察被视为解决 P 所需的基本信息。随后,提示 LLM 以便其运用或整合 C^1_i 中的观察,生成新的观察结果。
此过程可以不断延续,然而由于计算资源的限制,树的深度在达到 2 时便停止进一步扩展。
3. 将观察转化为代码
在获得观察后,需将其落实为具体的思路,随后再将这些思路转化为代码。
具体而言,对于每一个叶节点,团队会将所有的观察结果与原始问题 P 结合在一起,利用提示词来调用 LLM,从而生成针对问题 P 的自然语言解答。为了增加生成内容的多样性,团队还假设某个思路可能是错误的,并据此创造出一个额外的想法,进而请求 LLM 提供反馈或批评,最终使得提议的思路数量翻倍。
接下来,这些自然语言的解决方案会被翻译成伪代码,之后再将这些伪代码转换为实际的 Python 代码。
实验设计
本次实验使用了三个评估标准:MBPP+、HumanEval+ 和 LiveCodeBench。有关参数设置及其他细节,请参考原始论文。
关于实验结果,研究团队展示了三种方法的效果,包括重复采样、思路搜索及规划搜索,相关数据可见于表1、图1及图5。
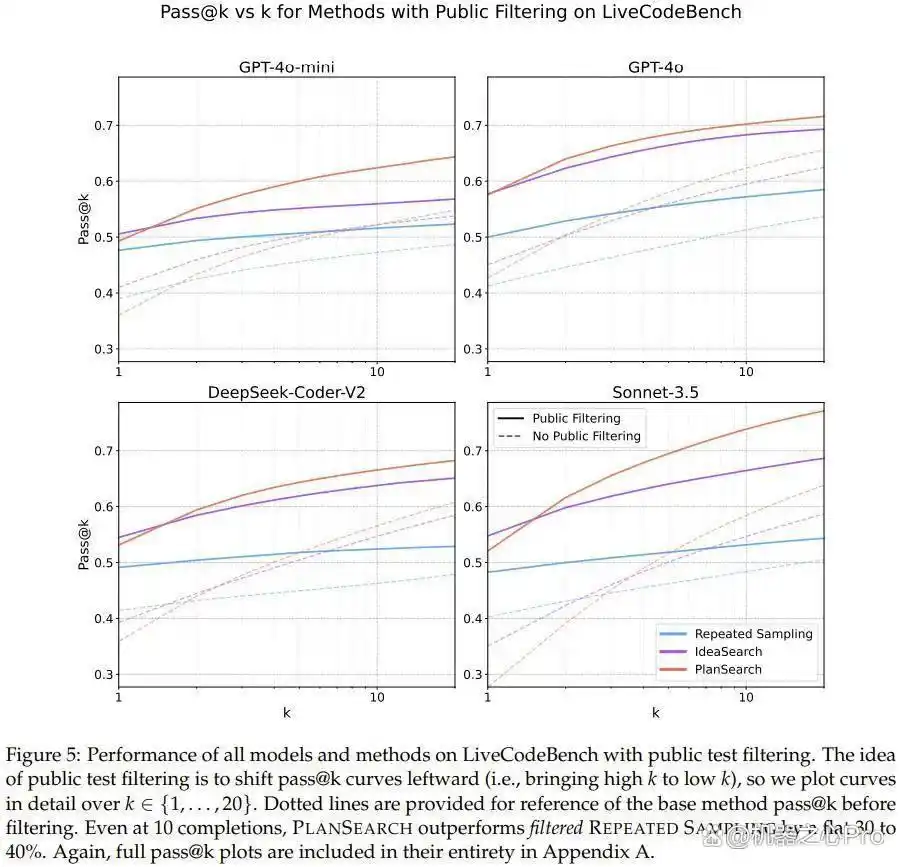
结果表明,规划搜索和思路搜索的性能显著超过了基础的采样方法,其中规划搜索在所有实验和模型中均表现出色,取得了最佳成绩。
图7、8、9展示了各数据集的详细 pass@k 结果。
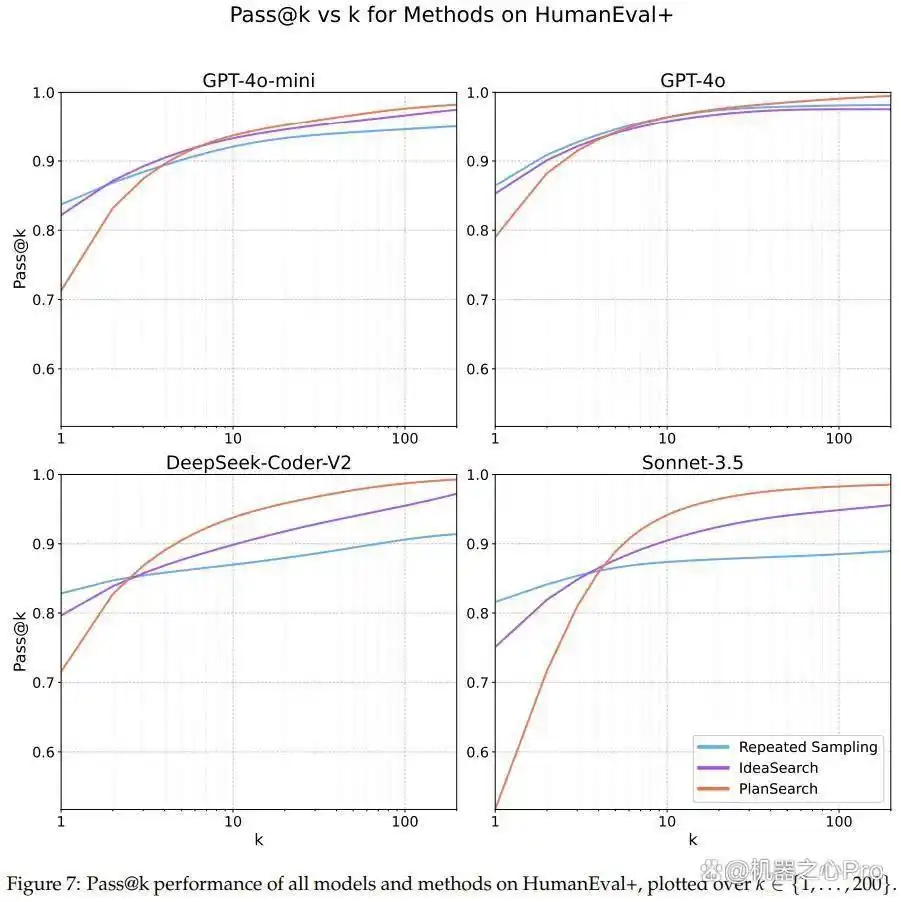
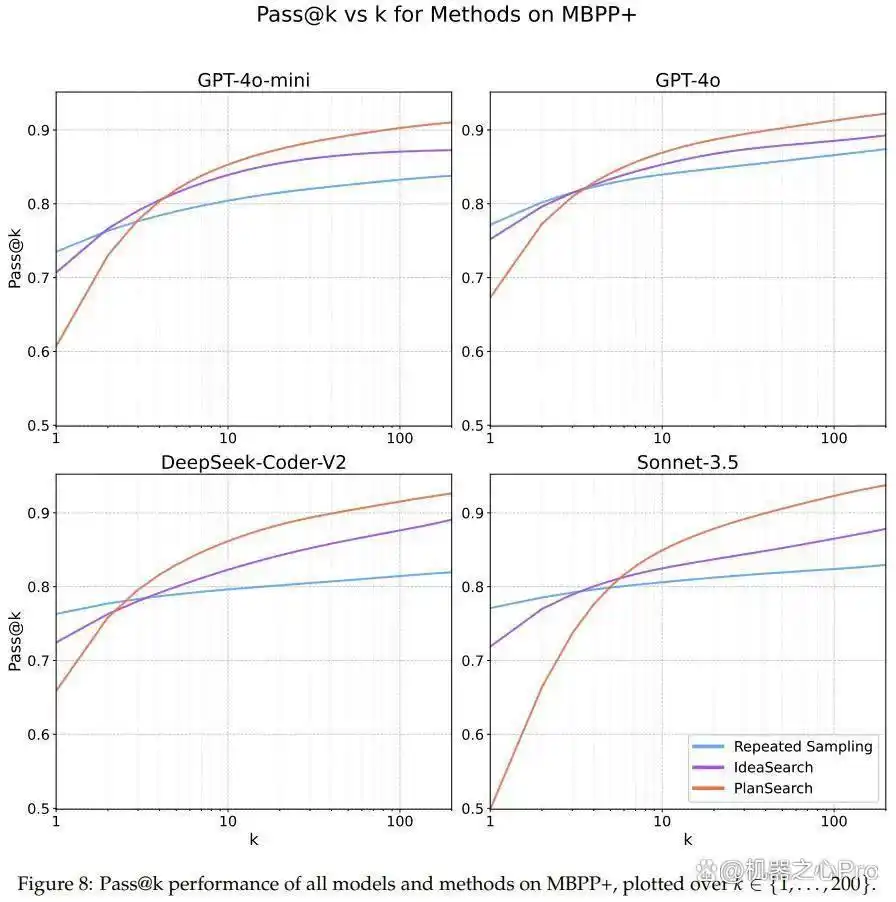
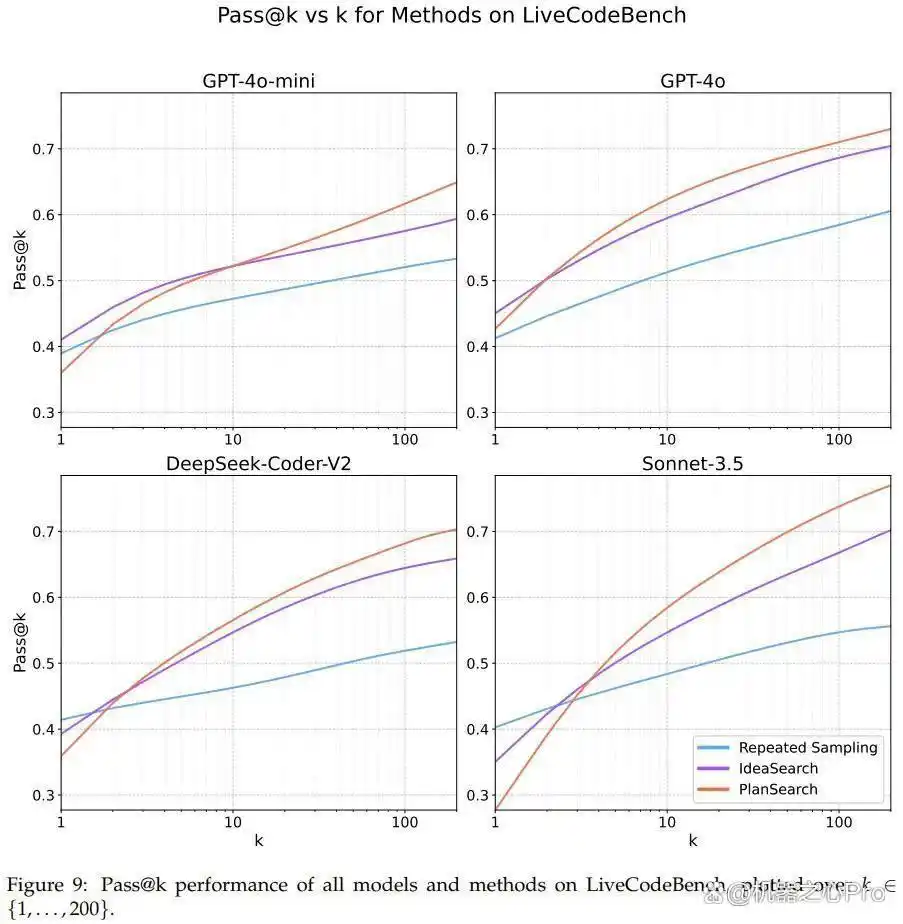
规划搜索在模型表现中的重要性
通过分析,我们发现当在 Claude 3.5 Sonnet 上应用规划搜索策略时,LiveCodeBench 基准测试的 pass@200 性能达到了令人瞩目的 77.0%。这一结果显然超越了未使用搜索方法时的最佳成绩(pass@1 = 41.4%)以及标准的 best-of-n 采样方法所获得的分数(pass@200 = 60.6%)。
另外,利用小型模型(如 GPT-4o-mini)进行规划搜索时,仅需进行 4 次尝试,便已超过了未采取搜索增强措施的大型模型的表现。这一现象支持了近来关于小模型进行搜索有效性的研究结论。
在其他编程基准,如 HumanEval+ 和 MBPP+,同样发现规划搜索带来了显著的性能提升。
通过对不同模型的比较,该团队意识到 pass@k 曲线的动态变化在各个模型中并不相同,实际上每条曲线展现出的特征各异。团队推测,这可能与思路多样性的差异有关。
有趣的是,该团队还观察到,规划搜索在某些模型的 pass@1 指标上并未带来益处,尤其是在 Sonnet 3.5 于 LiveCodeBench 上的表现上,这一组合在实验中表现最佳。
基于直觉,该团队提出了一个解释:尽管思路的多样性提升可能会降低特定思路生成的概率,但却提高了至少存在一个正确思路的机会。因此,pass@1 可能略显不足,而 pass@k 指标则因多样性的推动表现得更为出色。
此外,表 1 和图 1 显示了在尝试和完成方面经过归一化的主要结果。每种搜索方法都能针对每个问题尝试 k 次。
最后,该团队还发现,观察到的思路空间多样性能够有效预测搜索性能,这一关系可以通过模型与方法的 pass@1 和 pass@200 之间的相对改进来衡量,如图 6 所示。
重新审视多样性度量:熵的局限与新的计算方法
尽管熵作为多样性衡量的常用指标被广泛应用,但因其自身的局限性,无法精准地反映大型语言模型(LLM)中的多样性。
因此,研究小组通过在所有生成的程序中应用一种简易的配对策略,来量化多样性,并进一步将其放置于思路空间中进行分析。有关具体算法的详细信息,可参阅原始论文。

Please specify source if reproduced揭开Cursor编程的秘密武器:如何突破Scaling Law瓶颈? | AI工具导航