
随着人工智能技术的迅猛进步,像ChatGPT这样的庞大模型已经成为该领域的焦点。然而,这些看似具有“智慧”的创作行为,其背后却蕴藏着复杂的机械逻辑与技术架构。本文将深入探讨AI大模型的奥秘,包括Chat的意义、LLM(大型语言模型)的定义、Token的计算方式以及蒸馏模型的作用,供大家学习与参考。

当人工智能开始对话时,机器的思维究竟是如何运作的?
在凌晨三点的服务器机房,成千上万的显卡在漆黑的环境中闪烁着微弱的蓝色光芒,神经网络不停进行着每秒数万亿次的复杂计算。当ChatGPT为用户创作出一首精美的俳句,或是Comfy UI的工作流程产生出令人惊艳的数字艺术时,这些看似富有“灵性”的创作行为,其实都在运作着如同精密时钟般的机械逻辑。
仔细观察后,我们会发现大模型并非外界所理解的那样简单。
例如,在使用「Deepseek」进行API充值时,常常会看到“每百万token收费xx元”的提示,或者在本地部署时提到的「满血版」「32B」等术语。这些到底意味着什么呢?
接下来,我将作为一名自认为站在大模型前沿的作者,带领大家揭开大模型的神秘面纱,深入剖析其背后的秘密。
Chat的真正含义
自2023年起,随着AI技术的爆发,各种大模型如雨后春笋般涌现,尤其是在国内,已有超过百家机构推出相关模型。然而,细心的朋友会注意到,大多数大模型的网址域名中都有一个词「Chat」。

实际上,在大模型中“Chat”所指的就是模型具备的对话能力,意味着它可以像人类一样进行自然流畅的交流。
1)Chat=对话在大模型的语境中,“Chat”代表着模型与用户之间进行多轮对话交互的能力。
这样的对话不仅仅是简单的问答,而是能够理解上下文、记忆对话历史并给出自然且连贯的回应。
2)Chat 也象征着模型的应用领域
例如ChatGPT,其中“Chat”强调了其主要功能为聊天与对话,而GPT则是“Generative Pre-trained Transformer”(生成式预训练变换模型)的缩写。
举个例子:ChatGPT是一个对话机器人,其核心技术便是大模型,后者本身并不具备对话能力,而是通过“Chat”实现了与用户交流的功能,二者是有本质区别的。
总结而言,在AI大模型中,Chat代表了模型的“对话交互能力”,使得模型不仅能“生成文字”,还能够与用户实现连贯且智能的交流,从而提升互动体验。
LLM的定义
LLM是Large Language Model的缩写,也就是大型语言模型。在日常生活中,我们习惯使用这个缩写「LLM」。
1)核心特征
- 规模庞大:拥有数十亿到数万亿个参数。
- 训练数据丰富:通常基于互联网海量文本数据进行训练,包括书籍、文章、网页等。
- 多样化功能:可以完成文本生成、翻译、总结、问答、对话、编程等多种任务。
- 自我学习能力:通过“预测下一个词”的简单方式进行自我学习,逐步掌握语言规律。
2)工作原理
- 输入:用户提供一段文字,称为“Prompt”。
- Token 处理:LLM将输入文本拆分为Token。
- 预测:模型根据已有的Token,预测下一个最合适的Token。
- 输出:逐步生成完整的文本内容。
以上步骤实际上就是在与大模型互动时,用户提出问题后模型给出回答的整个流程。
3)代表模型
Token究竟是什么?
提到“token”这个词,很多人并不会感到陌生。例如,在使用“Deepseek”进行API充值时,常会看到明确标示:“每百万token的输入费用为xx元,而输出费用为xxx元”。那么,token到底指的是什么?为什么使用大模型时的费用计算要依赖token呢?
下面是“Deepseek”的token计费模式的具体信息。
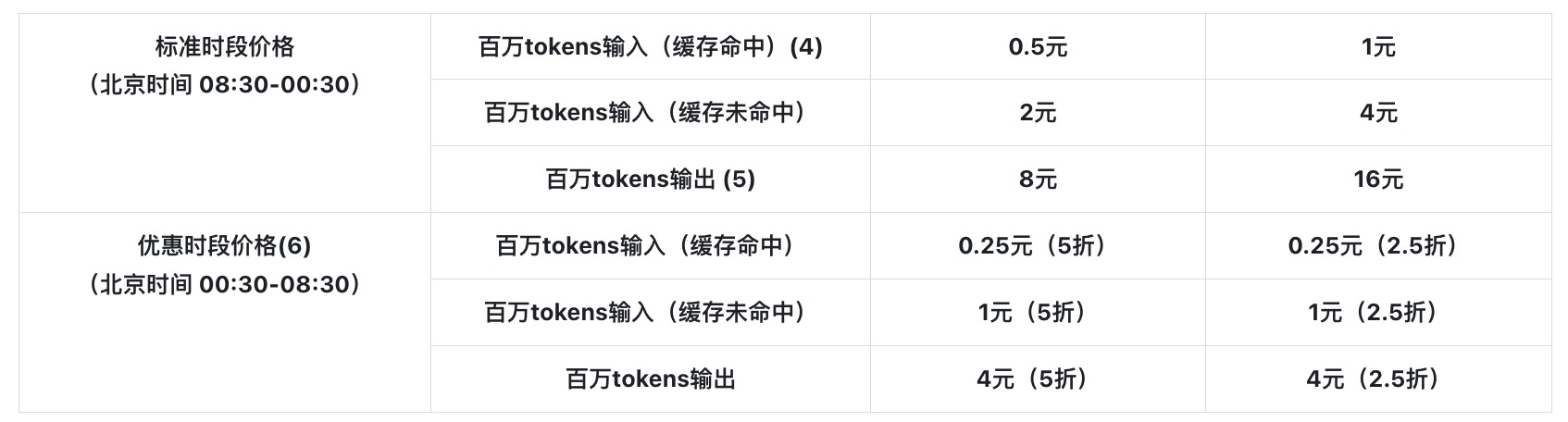
1)Token的定义
在大模型的背景下,Token(标记)是模型在处理文本时的基本单位。训练和推理过程中,大模型并不直接处理整段文本,而是将其拆分为一系列的Token,随后再进行分析和生成。
Token的概念是什么?
Token与字符的区别,Token不仅可以是一个字符,还可以是一个词,甚至是词的一部分。
Token的拆分方式取决于所采用的分词算法,常见的算法有以下两种:
- 字节对编码(BPE):通常应用于英文,将词按子词进行拆分。
- SentencePiece:支持多种语言,能够更智能地拆分文本。
2)Token的计算标准是什么?
Token并没有固定的字数限制,例如两个字可能是一个Token,三个字或四个字也可能被视为一个Token。
值得注意的是,英文与中文的Token计算方式存在差异。
例如:
英文句子示例
句子:ChatGPT is amazing!
Token拆分(根据BPE算法可能为):['Chat', 'G', 'PT', ' is', ' amazing', '!']
在这个例子中,ChatGPT被拆分为 'Chat'、'G' 和 'PT',而is和amazing则分别作为独立的Token。
中文句子示例
句子:大模型很厉害。
Token拆分(中文通常按字拆分):['大', '模型', '很', '厉害', '。']
在中文中,"模型"和"厉害"可能被整体作为Token,也可能被拆分,这取决于模型的训练数据。
如果想了解一段文本中的Token数量,可以使用OpenAI提供的Tokenizer工具进行测试,网址为:
https://platform.openai.com/tokenizer
根据我的调研以及与从事AI领域的朋友交流,普通人提问时通常在10-30个字之间。一个汉字大约相当于0.6个Token,具体情况还需根据汉字的复杂程度而定,最高可达一个汉字一个Token。同时,上下文的聊天记录和生成的输出也会计入Token的总数。
Token的重要性何在?
- 计费依据:如ChatGPT等模型一般是按照Token数量进行收费的。
- 模型限制:每种模型都有最大Token长度的限制,例如GPT-4的上下文长度为128k Token。
- 输出预测:模型生成的每一次输出都是基于现有Token来预测下一个Token。
那么,大模型是如何计算Token的呢?
前面提到,大模型会将文本的字数分解为不同的Token,而这一过程依赖于一种工具——分词器。
分词器(Tokenizer):其功能是将自然语言文本拆分为Token并将其映射为模型能够理解的数字ID。
分词器与Token之间的关系如下:
- 分词器负责生成Token,并将其转换为数值以供模型使用。
- 在模型的训练与推理过程中,输入和输出的基本单位都是Token。
综上所述,分词器是将文本转化为Token的工具,而Token则是模型理解和处理信息的基本单元。分词器的效率和准确性直接影响到模型的性能和效果。
探讨蒸馏模型的定义与重要性
蒸馏模型(Knowledge Distillation Model)是一种用于模型压缩的技术。它通过把大型模型(即教师模型,Teacher Model)的知识转移至一个更精简且轻便的模型(即学生模型,Student Model),以此提升小模型的性能,同时降低其计算资源的消耗。
简单来说,蒸馏模型就是在原有大型模型的基础上提炼出的一个小型模型。这个“蒸馏”过程使得新模型变得更精简、更高效。
为何需要蒸馏模型呢?
- 大型模型(Teacher Model):虽然其准确性很高,但体积庞大、推理速度慢且部署成本高昂。
- 小型模型(Student Model):尽管轻量,但其准确性可能不如大型模型。
- 模型蒸馏:通过提取大型模型中的知识,教导小型模型,使其在体积更小的情况下,接近大型模型的表现。
示例:本地部署Deepseek-R1-(完整版本)671B → Deepseek-R1-Distil-70B
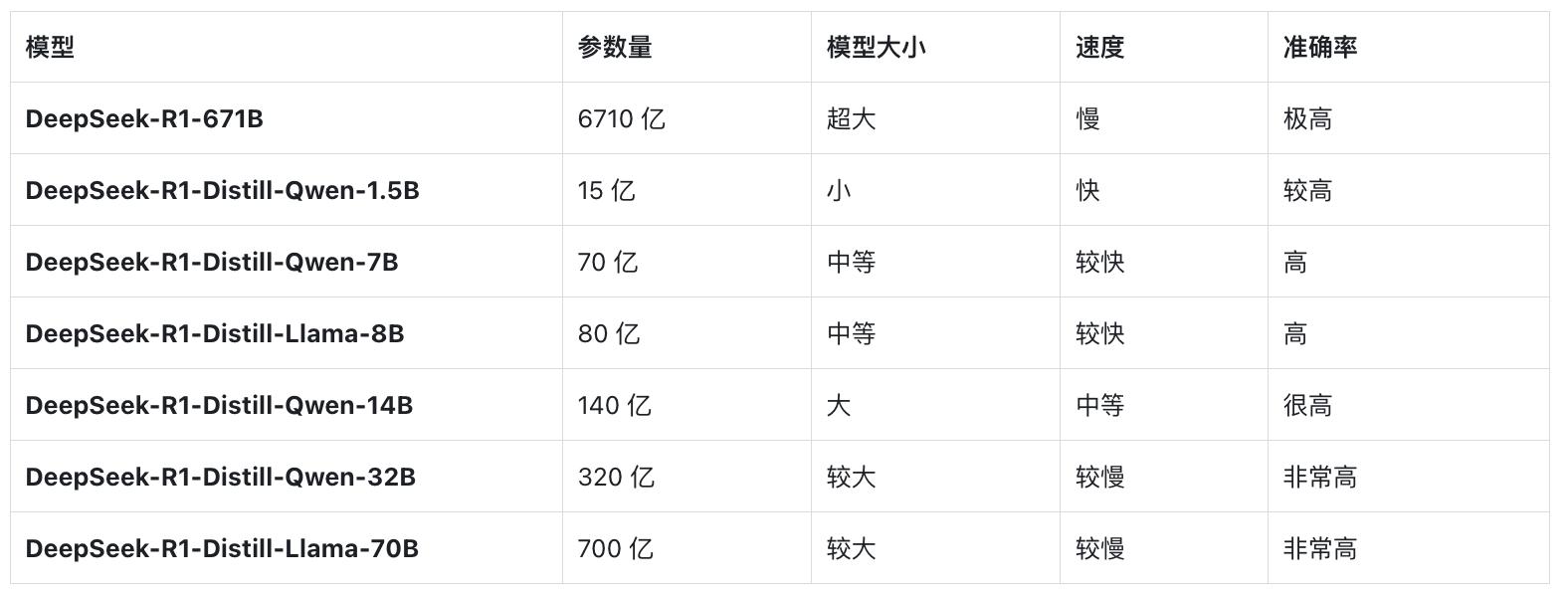
类似于Lora模型,它通常是在一个基础模型的框架下进行优化,可能是具有58亿或120亿参数的大型模型,这类模型一般在中小企业中使用较少,因此只需在大型模型的基础上优化出一个小型模型,适用于特定领域如医疗、出海等。
参数的定义与作用
在大型模型(例如大型语言模型,LLM)中,参数(Parameters)指的是模型可学习的权重值,这些值用于决定模型如何处理和理解输入数据。
主要功能包括:
- 权重与偏差:每个神经网络层中的神经元都有其对应的权重(Weight)和偏差(Bias)。这些参数在训练过程中不断调整,以减少模型预测与实际结果之间的误差。
- 知识的学习:模型通过大量数据的训练,将数据中的模式与规律“记忆”到这些参数中。通常,参数越多,模型捕捉数据细节的能力也就越强。
- 规模与能力:一般来看,参数数量越多,模型的表达能力越强,能够处理更复杂的语言和任务。
- 计算资源及成本:参数数量多意味着模型体积更大,训练与推理所需的计算资源和时间也会增加。
大模型中的参数是其学习的核心元素,决定了模型的能力边界、性能表现和计算成本。参数数量的增加通常意味着模型能力的增强,但同时也需要更高的硬件资源和优化策略。
举例说明:
思维链的定义与挑战
思维链(Chain of Thought,简称 CoT)是一种旨在提升大规模模型推理能力的技术。它的核心在于引导模型在处理复杂问题时,逐步呈现中间推理过程,而非仅仅给出最终结果。
该技术的重要性不言而喻。
在传统推理过程中,模型往往直接给出答案。然而,当面对逻辑推理、数学计算或复杂问答时,单步回答的方式常常导致错误。
通过引导模型分步骤进行思考,思维链能够实现以下几点:
- 提高准确性:逐步推理可以有效避免遗漏关键步骤,进而得出更为准确的结果。
- 增加可解释性:模型的推理过程变得更加透明,便于用户进行验证和优化。
- 降低计算开销:通过简化推理流程,有助于减少错误和重复计算的情况。
举例说明:
问题:小明最初有 3 个苹果,随后他又买了 5 个,最后吃掉了 2 个。那么他现在有多少个苹果呢?
普通回答:6 个。
思维链回答:
- 小明起初拥有 3 个苹果。
- 他又购买了 5 个苹果,因此现在他有 3 + 5 = 8 个苹果。
- 他吃掉了 2 个苹果,所以剩下的苹果数量是 8 – 2 = 6 个。
最终答案:6 个。
目前,市面上哪些模型支持思维链技术呢?
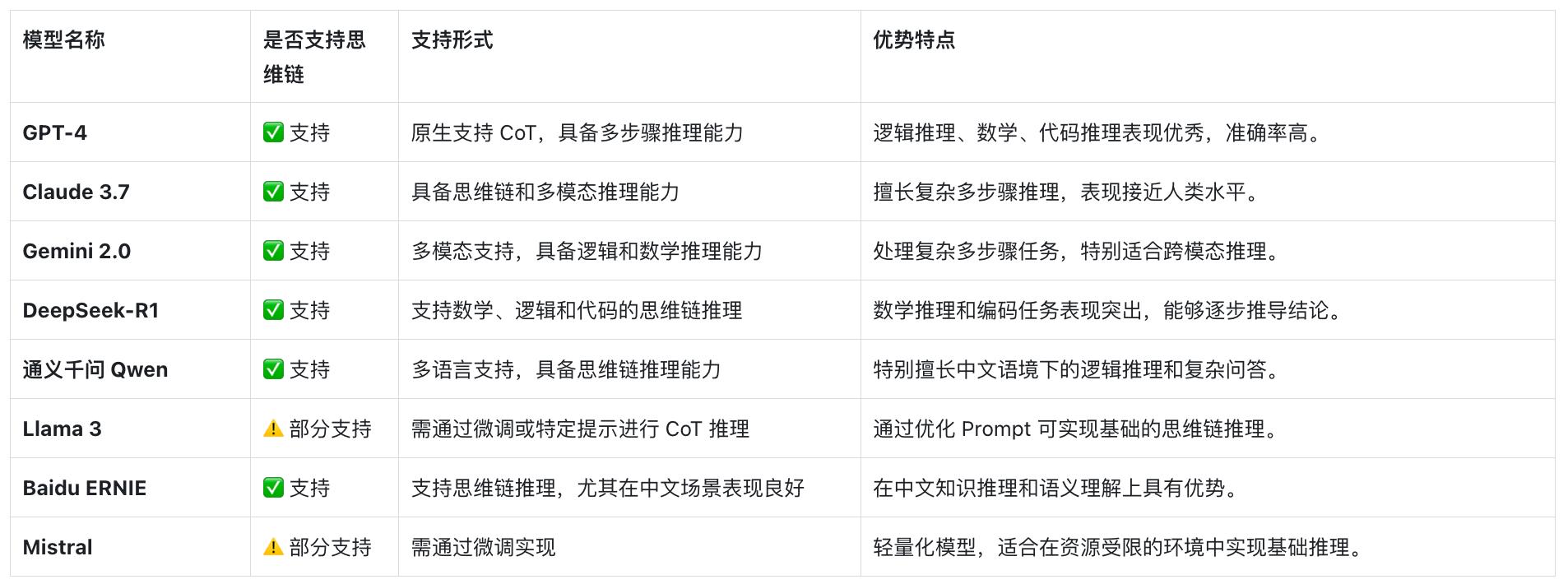
原生支持:如GPT-4、Claude 3、Gemini 1.5、DeepSeek-R1、通义千问等,无需额外优化即可实现高效的思维链推理。
部分支持:例如Llama 2、Mistral,这些模型需要通过提示优化或额外训练,才能有效进行思维链推理。
需要指出的是,许多大模型在DeepSeek开源之后,逐渐开始支持思维链技术。
总结
以上是笔者对大模型相关知识的分享。在这个人工智能迅速发展的时代,增强对AI的理解显得尤为重要。
期待下次再见!
本文由 @A ad钙 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,依据CC0协议发布。
文中观点仅代表作者个人,人人都是产品经理平台仅提供信息存储空间服务。

Please specify source if reproduced揭秘AI大模型:深度解析其背后的秘密与应用 | AI工具导航